
The Infra Play #117: Value accrues at the bottom of the stack
The latest earnings calls for AWS, Azure, and GCP were revealing in many ways. High growth, high stakes, high pace. Let's dive in.
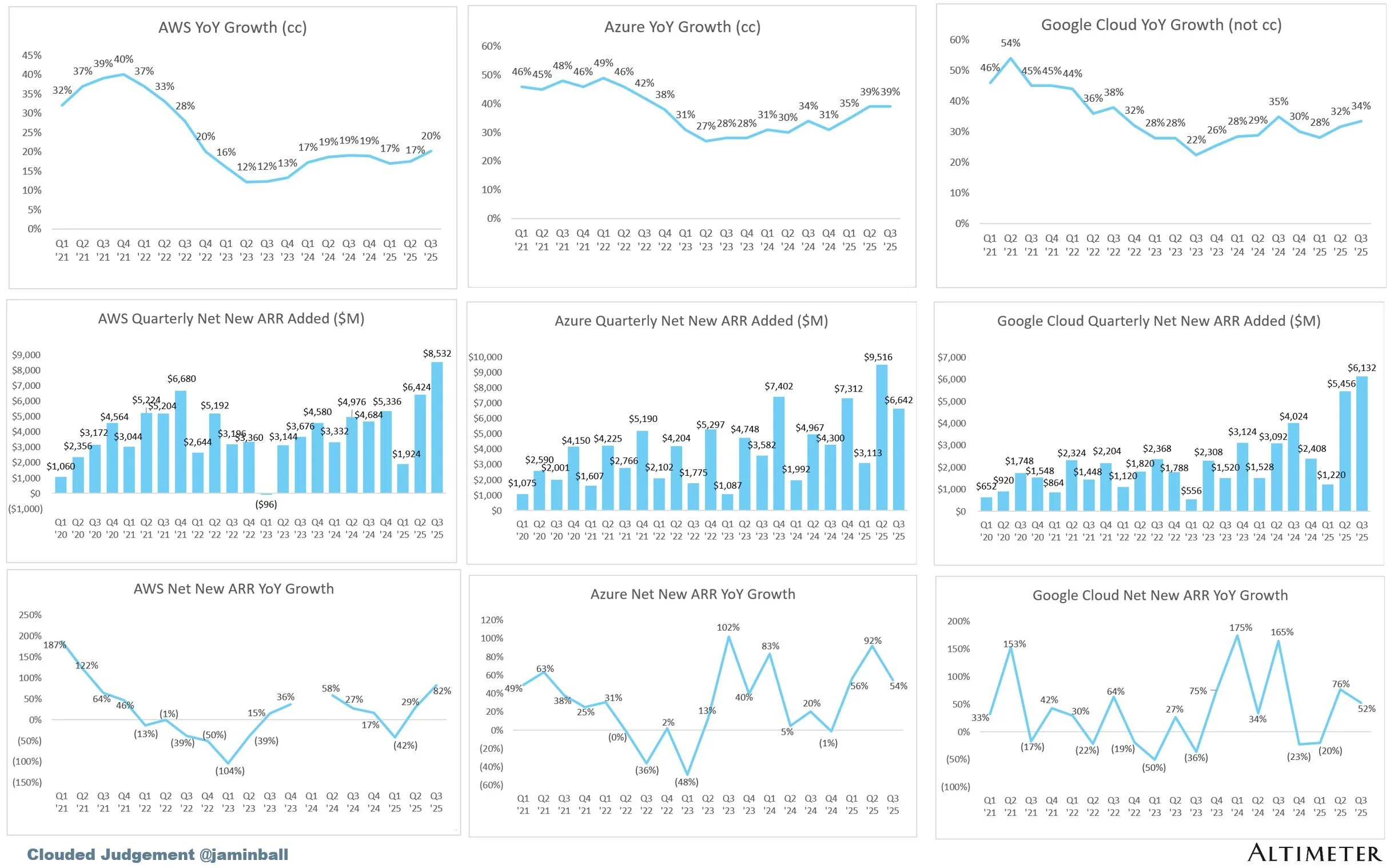
Source: Clouded Judgement on Substack
The key takeaway
For tech sales and industry operators: Success in the age of AI requires you to be where the tokens are flowing and can be monetized for a higher margin. This is particularly important at a time when there are power laws at play and it appears that while we are not in a "winner takes all" environment, we are definitely in a "winner takes most" situation. All three hyperscalers are trying to drive moats of their own, but Azure stands out due to having the best enterprise distribution, competitive and fungible infrastructure, large ownership and IP control over the most advanced frontier lab in the business, and strong synergy with the rest of their software business.
For investors and founders: For anybody building in the space, it should be clear that the bottom of the stack is currently accruing the majority of the value and this is likely to remain the key dynamic over the next years. This means that building in the middle is the worst way to operate; you need to pivot towards a strong infrastructure play (for which you are likely severely underfunded) or generate extreme differentiation in the application layer (proprietary data moats or vertical agents that incumbents can't easily replicate). This dynamic will likely persist for years as scaling laws continue: each model generation becomes more capable at specialized tasks, progressively commoditizing middleware solutions that once provided differentiation. From an investor perspective, Microsoft offers the highest-conviction play with proven enterprise traction and expanding Copilot ARPUs, but portfolio construction should include GCP for technical upside optionality and AWS for defensive diversification. The challenge for most investors is that direct exposure to frontier labs (OpenAI, Anthropic, xAI) remains trapped in private markets with limited access. The closest liquid proxy is the hyperscalers themselves, which is why the infrastructure thesis isn't just about where value accrues, but about where retail investors can actually capture it.
AWS
After what's been a humbling first half of the year in both market perception and practical outcomes, AWS finally had a good quarter where it came back to adding higher net new ARR than Azure.
Andy Jassy, CEO, Amazon: Backlog grew to $200 billion by Q3 quarter end and doesn’t include several unannounced new deals in October, which together are more than our total deal volume for all of Q3. AWS is gaining momentum. Customers want to be running their core and AI workloads in AWS, given its stronger functionality, security, and operational performance. The scale I see in front of us gives me significant confidence in what lies ahead. I’ll share a little more detail on why. It starts with AWS having much broader infrastructure functionality. Startups, enterprises, and governments want to move their production workloads to the place that has the broadest and deepest array of capabilities. AWS has more services and deeper features within those services than anybody else and continues to innovate at a rapid clip.
Companies will also use others’ agents, and AWS continues to build many of the agents we believe builders will use in the future. For coding, we’ve recently opened up our agentic coding IDE called Kiro. More than 100,000 developers jumped into Kro in just the first few days of preview, and that number has more than doubled since. It’s processed trillions of tokens thus far, weekly actives are growing fast, and developers love its unique spec and tool calling capabilities. For migration and transformation, we offer an agent called Transform. Year to date, customers have already used it to save 700,000 hours of manual effort, the equivalent of 335 developer years of work. For example, Thomson Reuters used it to transform 1.5 million lines of code per month, moving from Windows to open-source alternatives and completing tasks four times faster than with other migration tools.
Customers have also already used Transform to analyze nearly a billion lines of mainframe code as they move mainframe applications to the cloud. For business customers, we’ve recently launched QuickSleep to bring a consumer AI-like experience to work, making it easy to find insights, conduct deep research, automate tasks, visualize data, and take actions. We’ve already seen users turn months-long projects into days, get 80%+ time savings on complex tasks, and realize 90%+ cost savings. For contact centers, we offer Amazon Connect, which creates a more personalized and efficient experience for contact center agents, managers, and their customers. Connect has recently crested a $1 billion annualized revenue run rate, with 12 billion minutes of customer interactions being handled by AI in the last year and is being used by large enterprises like Capital One, Toyota, American Airlines, and Ryanair.
These are real, practical results for customers, and there are many more examples like them. Because of its advantaged capabilities, security, operational performance, and customer focus, AWS continues to earn most of the big enterprise and government transformations to the cloud. As a result, AWS is where the preponderance of companies’ data and workloads reside and part of why most companies want to run AI in AWS. To enable customers to do so, we need to have the requisite capacity, and we’ve been focused on accelerating capacity the last several months, adding more than 3.8 gigawatts of power in the past 12 months, more than any other cloud provider. To put that into perspective, we’re now double the power capacity that AWS was in 2022, and we’re on track to double again by 2027.
In the last quarter of this year alone, we expect to add at least another 1 gigawatt of power. This capacity consists of power, data center, and chips, primarily our custom silicon Trainium and NVIDIA. We’ve recently brought Project Rainier online, our massive AI compute cluster spanning multiple U.S. data centers and containing nearly 500,000 of our Trainium 2 chips. Anthropic is using it now to build and deploy its industry-leading AI model, Claude, which we expect to be on more than 1 million Trainium 2 chips by year-end. Trainium 2 continues to see strong adoption, is fully subscribed, and is now a multi-billion-dollar business that grew 150% quarter over quarter. Today, Trainium is being used by a small number of very large customers, but we expect to accommodate more customers starting with Trainium 3.
We’re building Amazon Bedrock to be the biggest inference engine in the world, and in the long run, believe Bedrock could be as big a business for AWS as EC2, and the majority of token usage in Amazon Bedrock is already running on Trainium. We’re also continuing to work closely with chip partners like NVIDIA, with whom we continue to order very significant amounts, as well as with AMD and Intel. These are very important partners with whom we expect to keep growing our relationships over time. You’re going to see us continue to be very aggressive investing in capacity because we see the demand. As fast as we’re adding capacity right now, we’re monetizing it. It’s still quite early and represents an unusual opportunity for customers in AWS.
This is a mix of bullish and bearish signals. The bullish part is mostly around the additional compute they've been able to add (3.8GW) and the strong focus on Trainium chips, both for use by Anthropic as well as internal workloads via Bedrock.
The bearish part, which he doesn't address but instead tries to gloss over, is the weak sentiment and developer adoption of AWS AI-related tools and inference. AWS Bedrock consistently ranks as one of the worst options for hosting models in terms of tokens per second and overall service performance, while tools like Kiro IDE have been met with lukewarm to hostile responses from developers. One of the biggest critiques is that the entire product design prioritizes massive scoping and planning descriptions that can be audited over speed or code quality. Developers want to build things, and AWS's primary way of helping them is by documenting every single step in the process ad nauseam. In a way, Kiro reflects the overall weakness and poor strategy of AWS when it comes to AI.
Justin Post: I'll ask on AWS. Can you just kind of go through how you're feeling about your capacity levels and how capacity constrained you are right now? And then in your prepared remarks, you mentioned Trainium 3 demand and maybe broadening out your customer base. Can you talk about the demand you're seeing outside of your major customers for Trainium?
Andrew Jassy: Yes. On the capacity side, we brought in quite a bit of capacity, as I mentioned in my opening comments, 3.8 gigawatts of capacity in the last year with another gigawatt plus coming in the fourth quarter and we expect to double our overall capacity by the end of 2027. So we're bringing in quite a bit of capacity today, overall in the industry, maybe the bottleneck is power. I think at some point, it may move to chips, but we're bringing in quite a bit of capacity. And as fast as we're bringing in right now, we are monetizing it. And then on the Trainium demand, outside of our major customers.
So first of all, as I mentioned on Trainium 2, it's really doing well. It's fully subscribed on Trainium2. We have -- it's a multibillion-dollar business at this point. It grew 150% quarter-over-quarter in revenue. And you see really big projects at scale now, like our Project Rainier that we're doing with Anthropic, where they're running their next version of -- they're training the next version of Claude on top of Trainium 2 on 500,000 Trainium 2 chips going to 1 million Trainium 2 chips by the end of the year. As I mentioned, we have -- today, with Trainium 2, we have a small number of very large customers on it.
But because Trainium is 30% to 40% more price performance than other options out there, and because as customers, as they start to contemplate broader scale of their production workloads, moving to being AI-focused and using inference, they badly care about price performance. And so we have a lot of demand for Trainium. Trainium 3 should preview at the end of this year with much fuller volumes coming in the beginning of '26, we have a lot of customers, both very large, and I'll call it, medium-sized who're quite interested in Trainium 3.
Operator: And the next question comes from the line of Brian Nowak with Morgan Stanley.
Brian Nowak: Congrats on the quarter, guys. So maybe 2. One, Andy, sort of a philosophical chip question. There's a lot of questions in the market about Trainium and sort of its positioning versus other third-party chips. So how do you think about the key hurdles of Trainium3 need to overcome to really make Trainium adoption broader, to your point on the last question and continue to drive Trainium as opposed to satisfying what could be broader demand with third-party chips in the near term?
Andrew Jassy: Yes. Well, first of all, we're always going to have multiple chip options for our customers. It's been true in every major technology building block or component that we've had in AWS. Really in the history of AWS, it's never just one player that over a long period of time has the entire market segment and then can satisfy everybody's needs on every dimension. And so we have a very deep relationship with NVIDIA. We have for a very long time. And we will for as long as I can foresee the future. We buy a lot of NVIDIA.
We are not constrained in any way in buying NVIDIA, and I expect that we'll continue to buy more NVIDIA both next year and in the future. But we're different from most technology companies in that we have our own very strong chip team, and this is our Annapurna team. And you saw it first on the CPU side with what we built with Graviton which is about 40% better price performance than the other x86 processors, and you're seeing it again on the custom silicon on the AI side with Trainium, which is about the same amount of price performance benefit for customers relative to other GPU options.
And our customers to be able to use AI as expansively as they want. And remember, it's still relatively early days at this point. They're going to need better price performance and they care about it deeply. And so I mentioned earlier the momentum that Trainium 2 has. And I think that for us, as we think about Trainium 3, I expect Trainium 3 will be about 40% better than Trainium 2 and Trainium 2 is already very advantaged on price performance. So we have to, of course, deliver the chip. We have to deliver it in volumes and deliver it quickly. And we have to continue to work on the software ecosystem, which gets better all the time.
And as we have more proof points like we have with Project Rainier with what Anthropic's doing on Trainium 2, it builds increasing credibility for Trainium. And I think customers are very bullish about it. I'm bullish about it as well.
Similar to Google, there is a focus on making custom chips that avoid paying the NVIDIA margin tax and allow them to fit 1GW of compute within a smaller budget than the $50B required when using NVIDIA over the lifecycle of the server rack. The demand seems to be coming mostly from Anthropic (which is not a bad thing, per se).
Colin Sebastian: I guess first on AWS, following up there. How much of this acceleration is driven by core infrastructure versus AI workload monetization? And I think part of it is trying to understand how important newer services like AgentCore are becoming and bringing enterprises to AWS to build agents? And then I guess, secondly, regarding the acceleration in advertising, if you could potentially disaggregate the core advertising contribution versus DSP and Prime video. That would be helpful as well.
Andrew Jassy: I'll start on the AWS side, we are seeing -- we're really pleased with the results from this quarter, 20% year-over-year on a annualized run rate of $132 billion is unusual. And we have momentum. You can see it. And we see the growth in both our AI area, where we see it in inference. We see it in training. We see it in the use of our Trainium custom silicon. Bedrock continues to grow really quickly. SageMaker continues to grow quickly. And I think that the number of companies who are working on building agents is very significant. I do believe that a lot of the value that companies will realize over time and AI will come from agents.
And I think that building agents today is still harder than it should be. You need tools to make it easier, which is why we built strands, which is an open source capability that lets people build agents from any model that they can imagine. But even more so, when you talk to enterprises or companies that care a lot about security and scale. They're starting to build agents, and they don't really feel like they've got -- they've had building blocks that allow them to have the type of secure scalable agents that they need to bet their businesses and their customer experience and their data.
And that's why -- that was really the inspiration behind AgentCore was to build another set of primitive building blocks like we built in the early days of AWS, where it was compute and storage and database. We defined a set of building blocks that you needed to be able to deploy agents securely and scalably that we provide in AgentCore. And then when we talk to our customers, it really resonates. There is not anything else like it, it's changing their time frame and their receptivity to building agents, and it's very compelling for them.
So I do think the combination of what we're doing to enable agents to be built and run securely and scalably as well as some of the agents that we're building ourselves that our customers are excited about are compelling for them. And I think the other place we see a lot of growth in AWS also is just the number of enterprises who are -- who have gotten back to moving from on-premises infrastructure to the cloud. And we continue to earn the lion's share of those transformations. And I look at the momentum we have right now, and I believe that we can continue to grow at a clip like this for a while.
The lack of specifics and avoiding directly answering the questions doesn't help. Currently it's more likely that the jump in revenue came from being able to deliver previous commitments as more compute became available, rather than from some sort of great organic adoption across the portfolio.
Azure
Source: The Deal Director on X
Satya Nadella: Thank you, Jonathan. It was a very strong start to our fiscal year. Microsoft Corporation Cloud revenue surpassed $49 billion, up 26% year over year, and our commercial RPO grew over 50% to nearly $400 billion with a weighted average duration of only two years. We are seeing increasing demand and diffusion of our AI platform and family of copilots, which is fueling our investments across both capital and talent. When it comes to infrastructure, we're building a planet-scale cloud and an AI factory, maximizing tokens per dollar per watt while supporting the sovereignty needs of customers and countries. We're innovating rapidly across the family of copilots spanning the high-value domains of information work, coding, security, science, health, and consumer.
And as you saw yesterday, we closed a new definitive agreement with OpenAI, marking the next chapter in what is one of the most successful partnerships and investments our industry has ever seen. This is a great milestone for both companies, and we continue to benefit mutually from each other's growth across multiple dimensions. Already, we have roughly 10x'd our investment, and OpenAI has contracted an incremental $250 billion of Azure services. Our revenue share, exclusive rights, and API exclusivity for Azure until AGI or through 2030. And we have extended the model and product IP rights through 2032. We are also energized to innovate and pursue AI advancements with both talent and compute investments that have real-world impact.
With that, let's turn to our momentum across our AI platform and copilots as well as with agents. We have the most expansive data center fleet for the AI era, and we are adding capacity at an unprecedented scale. We will increase our total AI capacity by over 80% this year and roughly double our total data center footprint over the next two years, reflecting the demand signals we see. Just this quarter, we announced the world's most powerful AI data center, Fairwater in Wisconsin, which will go online next year and scale to two gigawatts alone. We have deployed the world's first large-scale cluster of NVIDIA GB300s.
We are building a fungible fleet that's being continuously modernized and spans all stages of the AI lifecycle, from pre-training to post-training to synthetic data generation and inference. It also goes beyond Gen AI workloads to recommendation engines, databases, and streaming. We're optimizing this fleet across silicon, systems, and software to maximize performance and efficiency. It's this combination of fungibility and continuous optimization that allows us to deliver the best ROI and TCO for us and our customers. For example, during the quarter, we increased the token throughput for GP 4.1 and GPT-5, two of the most widely used models, by over 30% per GPU. We also have the most comprehensive digital sovereignty platform.
Azure customers in 33 countries are now developing their own cloud and AI capabilities within their borders to meet local data residency requirements. In Germany, for example, OpenAI and SAP will rely on Azure to deliver new AI solutions to the public sector. On top of this infrastructure, we're building Azure AI Foundry to help customers build their own AI apps and agents. We have 80,000 customers, including 80% of the Fortune 500. We offer developers and enterprises access to over 11,000 models, more than any other vendor, including as of this quarter, OpenAI's GPD-5 as well as XAI's GRAQ-4.
Ralph Lauren used Foundry to build a conversational shopping experience in its app, enabling customers to describe what they're looking for and get personalized recommendations. OpenEvidence used Foundry to create its AI-powered clinical assistant, which surfaces relevant medical information to physicians and helps streamline charting. When it comes to our first-party models, we are excited by the performance of our new MAI models for text, voice, and image generation, which debuted among the top in the industry leaderboards. We continue to make great progress with our Phi family of S SLMs, which now have been downloaded over 60 million times, up 3x year over year.
Beyond models and Foundry, we are providing everything developers need to design, customize, and manage AI applications and agents at scale. Our new Microsoft Agent Framework helps developers orchestrate multi-agent systems with compliance, observability, and deep integration out of the box. For example, KPMG used the framework to modernize the audit process, connecting agents to internal data with enterprise-grade governance and observability. These kinds of real production-scale AI deployments are driving Azure's overall growth. Once again, this quarter, Azure took share. Now let's turn to applications and agents we ourselves are building on this platform. We now have 900 million monthly active users of our AI features across our products.
Our first-party family of copilots now has surpassed 150 million monthly active users across information work, coding, security, science, health, and consumer. When it comes to information work, we continue to innovate with Microsoft 365 Copilot. Copilot is becoming the UI for the agentic AI experience. We have integrated chat and agentic workflows into everyday tools like Outlook, Word, Excel, PowerPoint, and Teams. Just nine months since release, tens of millions of users across Microsoft's 365 customer base are already using chat. Adoption is accelerating rapidly, growing 50% quarter over quarter, and we continue to see usage intensity increase.
This quarter, we also introduced agent mode, which turns single prompts into expert-quality Word documents, Excel spreadsheets, PowerPoint presentations, and then iterates to deliver the final product, much like agent mode in coding tools today. We're thrilled by the early response, including third-party benchmarks that rank it best in class. Beyond individual productivity, Copilot is multiplayer with Teams mode announced this week. You can now invite colleagues into a Copilot conversation. Our collaborative agents like facilitator and project manager prep meeting agendas, take notes, capture decisions, and kick off group tasks. We are seeing a growing Copilot agent ecosystem with top ISVs like Adobe, Asana, Jira, LexisNexis, ServiceNow, Snowflake, and Workday all building their own agents that connect to Copilot.
Customers are also building agents for their mission-critical business processes and workflows using tools like Copilot Studio, integrating them into Copilot. The overall number of agent users doubled quarter over quarter, and just yesterday we announced App Builder, a new copilot agent that lets anyone create and deploy task-specific apps and agents in minutes grounded in Microsoft 365 context. All this innovation is driving our momentum. Customers continue to adopt Microsoft 365 Copilot at a faster rate than any other new Microsoft 365 suite. All up, more than 90% of the Fortune 500 now use Microsoft 365 Copilot. Accenture, Bristol Myers Squibb, Global, and The UK's Tax and Payment and Customs Authority all purchased over 15,000 seats this quarter.
Lloyds Banking Group has deployed 30,000 seats, saving each employee an average of 46 minutes daily. A large majority of our enterprise customers continue to come back to purchase more seats. Our partner PwC alone added 155,000 seats this quarter and now has over 200,000 deployed across its global operations. In just six months, PwC employees interacted with Microsoft 365 Copilot over 30 million times, and they credit this agentic transformation with saving millions of hours in employee productivity. When it comes to coding, GitHub Copilot is the most popular AI pair programmer now with over 26 million users.
For example, tens of thousands of developers at AMD use GitHub Copilot, accepting hundreds of thousands of lines of code suggestions each month and crediting it with saving months of development time. All up, GitHub is now home to over 180 million developers, and the platform is growing at the fastest rate in its history, adding a developer every second. 80% of new developers on GitHub start with Copilot within the first week. Overall, the rise of AI coding agents is driving record usage with over 500 million pull requests merged over the past year. Just yesterday at GitHub Universe, we introduced AgentHQ.
GitHub Copilot and AgentHQ is the organizing layer for all coding agents, extending the GitHub primitives like PRs, issues, actions to coding agents from OpenAI, Anthropic, Google, Cognition, xAI, as well as OSS and in-house models. GitHub now provides a single mission control to launch, manage, and review these agents, each operating from its own branch with built-in controls, observability, and governance. We're building a similar system in security with over three dozen agents in Copilot integrated across Entra, Defender, Purview, and Intune. For example, with our phishing triage agent in Defender, studies show that analysts can be up to 6.5x more efficient in detecting malicious emails. In health, Dragon Copilot helps providers automate critical workflows.
This quarter alone, we helped document over 17 million patient encounters, up nearly 5x year over year. More than 650 healthcare organizations have our Ambient listening tech to date, including University of Michigan Health, where over 1,000 physicians are actively using it. Finally, when it comes to AI consumer experiences, we are excited about all the progress Copilot is making, starting with Windows. Every Windows 11 PC now is an AI PC. Just two weeks ago, we introduced new ways to speak naturally to your computer, including a Copilot wake word. With vision, Copilot sees what you see on your screen, and you can have a real-time conversation about it.
It should be immediately obvious here what "momentum" really looks like: crisp, specific examples of large-scale customers adopting Azure inference and native Copilot functionality across their full portfolio. The level of discussion is also completely different, as the first analyst question is about…AGI.
Keith Weiss: Excellent. Thank you guys for taking the question. Congratulations on another outstanding quarter. If I'm looking at Microsoft Corporation, this is two quarters in a row where we're really seeing results that are well ahead of anybody's expectations when we're thinking about this company a year ago or five years ago. 111% commercial bookings growth was not on anybody's bingo card, if you will. Yet the stock is underperforming the broader market. The question I have is kind of getting at the zeitgeist that I think is weighing on the stock. Is something about to change? I think AGI is kind of a nomenclature or a shorthand for that. It's something that's still included in your guys' OpenAI agreement.
So, Satya, when we think about AGI or we think about how application and computing architectures are changing, is there anything that you see on the horizon, whether it's AGI or something else, that could potentially change what appears to be a really strong positioning for Microsoft Corporation in the marketplace today where that strength will perhaps weaken on a go-forward basis? Is there anything that you're worrying about in that evolution, and particularly the evolution of these generative AI models?
Satya Nadella: Thank you, Keith, for the question. Here's what I would say. I think there are two parts. We feel very, very good about even this, I'd say, the new agreement that we now have with OpenAI. Because I think it just creates more certainty to all of the IP we have as it relates to even this definition of AGI. But beyond that, I think your question touches on something that's pretty important, which is how are these AI systems going to truly be deployed in the real world and make a real difference and make a return for both the customers who are deploying them and then obviously the providers of these systems.
I think the best way to characterize the situation is that even as the intelligence increases, let's even say exponentially, like model version over model version, the problem is it's always going to still be jagged. Right? I think the term people use is the jagged intelligence or spiky intelligence, right? So you may even have a capability that's fantastic at a particular task, but it may not uniformly grow. So what is required is, in fact, these systems, whether it is GitHub, AgentHQ, or the Microsoft 365 Copilot system. Don't think of this as a product, think of it as a system. That in some sense smooths out those jagged edges and really helps the capability.
I mean, just to give you a flavor for it. Right? So if I am in Microsoft 365 Copilot, I can generate an Excel spreadsheet. The good news is now an Excel spreadsheet does understand OfficeJS, has the formulas in it. It feels like, wow, it is a great spreadsheet created by a good modeler. The more interesting thing is I can go into agent mode in Excel, and iterate on that model. And yet it will stay on rails. It won't go off rails. It will be able to do the iteration. Then I can even give it to the analyst agent, and it will even make sense of it like a data analyst would of our Excel model.
The reason I say all of that is because that's the type of construction that will be needed even when the model is magical, all-powerful. I think we will be in this jagged intelligence phase for a long time. So one of the fundamental things that these, whether it's GitHub, it's whether it's Microsoft 365, the three main domains we're in, we feel very, very good about building these as organizing layers for agents to help customers. By the way, that's the same thing that we want to put into Foundry for our third-party customers. So that's kind of how people will build these multi-agent systems. So I feel actually pretty good about both the progress in AI.
I don't think AGI as defined, at least by us in our contract, is ever going to be achieved anytime soon. But I do believe we can drive a lot of value for customers with advances in AI models by building these systems. So it's kind of the real question that needs to be well understood. I feel very, very confident about our ability to make progress.
The AGI angle is quite critical here since it directly correlates to how long Microsoft can maintain access to the full IP of OpenAI. I wrote about it when I reviewed the new deal between the two companies.
What is AGI? According to a recent white-paper that includes Eric Schmidt as a co-author, the definition can be considered as "AGI is an AI that can match or exceed the cognitive versatility and proficiency of a well-educated adult."
Currently they rank GPT-5 performance relative to different benchmarks at 57% towards AGI. While there are many different ways to approach this, the proposal outlined here is a reasonable way to think about how an "independent panel" might benchmark this. In practical terms, this means it is likely that any "pronouncement" of AGI might happen in the 2030s, likely after some legal back-and-forth for a few years. Timelines are quite critical here:
Microsoft’s IP rights for both models and products are extended through 2032 and now includes models post-AGI, with appropriate safety guardrails.
Microsoft’s IP rights to research, defined as the confidential methods used in the development of models and systems, will remain until either the expert panel verifies AGI or through 2030, whichever is first. Research IP includes, for example, models intended for internal deployment or research only. Beyond that, research IP does not include model architecture, model weights, inference code, finetuning code, and any IP related to data center hardware and software; and Microsoft retains these non-Research IP rights.
Azure will remain the primary provider of OpenAI inference for business users until at least December 2032. The "include models post-AGI" clause is a bit peculiar; I assume it would imply that they retain IP rights for anything they've already gained access to up until that date, even if AGI is declared earlier.
After my article was published, Sam Altman also did a one-hour stream to discuss their strategy for getting to AGI, with this important insight:
We have set internal goals of having an automated AI research intern by September of 2026 running on hundreds of thousands of GPUs, and a true automated AI researcher by March of 2028. We may totally fail at this goal, but given the extraordinary potential impacts we think it is in the public interest to be transparent about this.
The “AI researcher” comes back to the core thesis of Situational Awareness that I wrote about and what appears to be the widely shared opinion in San Francisco, i.e., "we don't know how to build AGI, but we think that automating research would get us there":
We don’t need to automate everything—just AI research. A common objection to transformative impacts of AGI is that it will be hard for AI to do everything. Look at robotics, for instance, doubters say; that will be a gnarly problem, even if AI is cognitively at the levels of PhDs. Or take automating biology R&D, which might require lots of physical lab work and human experiments.
But we don’t need robotics—we don’t need many things—for AI to automate AI research. The jobs of AI researchers and engineers at leading labs can be done fully virtually and don’t run into real-world bottlenecks in the same way (though it will still be limited by compute, which I’ll address later). And the job of an AI researcher is fairly straightforward, in the grand scheme of things: read ML literature and come up with new questions or ideas, implement experiments to test those ideas, interpret the results, and repeat. This all seems squarely in the domain where simple extrapolations of current AI capabilities could easily take us to or beyond the levels of the best humans by the end of 2027.
It’s worth emphasizing just how straightforward and hacky some of the biggest machine learning breakthroughs of the last decade have been: “oh, just add some normalization” (LayerNorm/BatchNorm) or “do f(x)+x instead of f(x)” (residual connections)” or “fix an implementation bug” (Kaplan → Chinchilla scaling laws). AI research can be automated. And automating AI research is all it takes to kick off extraordinary feedback loops.
So while Satya is betting on AGI being another decade away, OpenAI is trying to get there by the negotiated timeline of 2032.
Brent Thill: Thanks. Amy, on the bookings blowout, I guess many are somewhat concerned about concentration risk. I think you noted a number of $100 million contracts. Not to go into a lot of detail, but can you just give us a sense of what you're seeing in that 51% RPO and 110% plus bookings growth that gives you confidence about what you're seeing in terms of the breadth and extent of some of these deals on a global basis? Thanks.
Amy E. Hood: Thanks, Brent. A couple of things to maybe take a step back. On RPO, with a nearly $400 billion balance, we've been trying to help people understand sort of how to think about really the breadth of that. It covers numerous products. It covers customers of all sizes. It cuts across multiple products because of things Satya's talking about around creating systems and where we're investing. If you're going to have that type of balance, and then more importantly, have the weighted average duration be two years, it means that most of that is being consumed in relatively short order. People are not consuming, and I say this broadly, unless there's value.
I think this is why we keep coming back to are we creating real-world value in our AI platforms, in our AI solutions and apps and systems. I think the way to think about RPO is it's been building across a number of customers. We're thrilled to have OpenAI be a piece of that. We're learning a ton and building leading systems because of it that are being used at scale that benefits every other customer. It's why we've tried to get a little bit more color to that RPO balance because I do understand that there have been a lot of concern or questions about is it long-dated, is it coming over a long period of time.
Hopefully, this is helpful for people to realize that these are contracts being signed by customers who intend to use it in relatively short order. At that type of scale, I think that's a pretty remarkable execution.
Azure reps are casually signing a number of $100M+ ARR commitments, predominantly for AI workloads.
Mark Moerdler: Thank you very much for taking my question and congratulations on the quarter. It's pretty amazing what you guys are doing. Satya and Amy, I'd like to ask you the number one question I receive, whether from investors or at AI conferences I attend. How much confidence do you have that the software, even the consumer Internet business, can monetize all the investments we're seeing globally, or frankly, are we in a bubble? In fact, Amy, what would be the factors you'd be watching for to assure that you're not overbuilding for current demand? And that demand will sustain. Thank you.
Amy E. Hood: Maybe I'll start, Satya, and then you could add. Let me talk a little bit about, maybe connecting a couple of the dots because $400 billion of RPO that's sort of short-dated as we talked about, our needs to continue to build out the infrastructure is very high. That's for booked business today. That is not any new booked business we started trying to accomplish on October 1, right? The way to think about that, and you saw it this quarter in particular and as we talked about twenty-six, the remainder, number one, we're pivoting toward increasingly, we talked about this short-lived assets, both GPUs and CPUs. Again, we talk about all these workloads are burning both.
In terms of app building. Now, when that happens, short-lived assets generally are done to match sort of the duration of the contracts or the duration of your expectations of those contracts. I sometimes think when people think about risk, they're not realizing that most of the lifetimes of these and the lifetimes of the contracts are very similar. When you think about having revenue and the bookings and coming on the balance sheet and the depreciation of short-lived assets, they're actually quite matched, Mark. As you know, we've spent the past few years not actually being short GPUs and GPUs per se, we were short the space or the power, as the language we use, to put them in.
So we spent a lot of time building out that infrastructure. Now we're continuing to do that also using leases. Those are very long-lived assets as we've talked about, fifteen to twenty years. Over that period of time, do I have confidence that we'll need to use all of that? It is very high. When I think about sort of balancing those things, seeing the pivot to GPU/CPU short-lived, seeing the pivot in terms of how those are being utilized. We are, and I said this now, we've been short now for many quarters. I thought we were going to catch up. We are not. Demand is increasing. It is not increasing in just one place.
It is increasing across many places. We're seeing usage increases in products. We're seeing new products launch that are getting increasing usage and increasing usage very quickly. When people see real value, they actually commit real usage. I sometimes think this is where this cycle needs to be thought through completely is that when you see these kinds of demand signals and we know we're behind, we do need to spend. But we're spending with a different amount of confidence in usage patterns and in bookings, and I feel very good about that. I have said we are now likely to be short capacity to serve the most important things we need to do, which is Azure, our first-party applications.
We need to invest in product R&D. We're doing end-of-life replacements in the fleet. So we're going to spend to make sure that happens. It's about modernization, it's about high quality, it's about service delivery, and it's about meeting demand. I feel good about doing that, and I feel good that we've been able to do it so efficiently and with a growing book of business behind it.
Satya Nadella: Yes. The only thing I would add to what Amy captured was you sort of look out there are two things that matter, I think. That are critical in terms of how we think about our allocation of capital and also our R&D. One is how efficient is our PlanetScale token factory. Right? I mean, that's at the end of the day, what you have to do. In order to do that, you have to start with building out a very fungible fleet. It's not like we're building one data center in one region in the world that's mega scale.
We're building it out across the globe for inference, for pre-training, for post-training, for RL, for data sense, or what have you. Therefore, that's the fungibility is super important. The second thing that we're also doing is modernizing the fleet. It's not like we buy one version of, say, NVIDIA and load up for all the gigawatts we have. Each year you buy, you ride the Moore's Law, you continuously modernize and depreciate. That means you also use software to grow efficiency. I talked about, I think, 30% improvement on both serving up GBD4.1 and five, right? That's software. That's sort of, and by the way, it's helpful on A100s. It's helpful on, and it will be helpful on GB300s.
That's the beauty of having the efficiency of the fleet. So keep improving utilization, keep improving the efficiency. That's what you do in the token factory. The other aspect which Amy spoke to is, we have some of the best agent systems that matter in the high-value domains. Right? It's in information work. That's the Copilot system. Coding, I should also say one of the things I like about Copilot is, I mean, Copilot ARPUs compared to Microsoft 365 ARPUs, right? It's expansive. The same thing that happened between server and cloud, like we used to always say, well, is it zero sum? It turned out that the cloud was so much more expansive to the server.
The same thing is happening in AI. Because first, you could say, hey, our ARPUs are too low. When it comes to Microsoft 365 or you could say, we have the opportunity with AI to be much more expansive. Same thing with tools, right? I mean, tools business was not like a leading business, whereas coding business is going to be one of the most expansive AI systems. We feel very good about being in that category. Same thing with security, same thing with health. In consumer, one of the things is it's not just about ads, it's ads plus subscriptions. That also opens up opportunity for us.
When I look at the entirety of these high-value agent systems, and when we look at the efficiency of and fungibility of our fleet, that's what gives us the confidence to invest both the capital and the R&D talent to go after this opportunity.
When provoked with an "is this a bubble?" question, the response is interesting. They're essentially saying "we have hundreds of billions in committed contracts, we can't build fast enough to meet current demand, and we're seeing real usage growth." Not to state the obvious, but Azure has double the revenue backlog of AWS at $400B.
Mark Murphy: Thank you so much. We seem to be entering into a new era where the contractual commitments from a small number of AI natives are just incredibly large, not only in absolute terms but sometimes relative to the size of the companies themselves. For instance, contracts worth hundreds of billions of dollars that are 20 times their current revenue scale. Philosophically, do you evaluate the ability of those companies to follow through on these commitments? How do you think about placing guardrails on customer concentration for any single entity?
Satya Nadella: Yes. Maybe I'll start and then maybe you can add. It goes back a little bit, Mark, to what I said about building first, the asset itself such that it's most fungible. Then to recognize the strength of even sort of our portfolio. We have a third-party business. We have a first-party business. We have third-party also spread between enterprise, digital natives. I always felt that we need a balance there because it may start with digital natives. They're always going to be the early adopters. You always have the hit app of the generation. Then essentially then it spreads throughout the enterprise adoption cycle is just starting.
Therefore, having the over the arc of time, I think that third-party balance of customers will only increase. But it's great to have the hit first-party apps in the beginning because you can build scale that then if it's fungible, and that's where the key is. You don't want to build for a digital native as if you're just doing hosting for them. You want to build. That's where some of the decision-making of ours is probably getting better understood. What do we say yes to? What do we say no to? I think there was a lot of confusion. Hopefully, by now, anyone who switched on would figure this out.
That's I think one thing we're doing on the third party. But the one first party is probably where a lot of our leverage comes, and it's not even about one hit app on our first-party event. Our portfolio stuff, which I just walked through in the earlier answer, gives us again the confidence that between that mix, we will be able to use our fleet to the maximum. Remember, these assets, especially the data centers and so on, are long, right? There will be many refresh cycles for any one of these when it comes to the gear.
I feel that once you think about all those dimensions, the concentration risk gets mitigated by being thoughtful about how you really ensure the build is for the broad customer base.
Amy E. Hood: Maybe just to help with another angle, Zach, because I think Satya has helped a lot. When you think about concentration risk for delivering to any customer, you have to remember that because we're talking about this very large flex fleet that can be used for anyone and for any purpose, 1P, 3P, and including our commercial cloud, by the way, which I should be quite clear on, it's pretty flexible in every regard. You have to remember that the CPU and GPU and the storage gear doesn't come into play until the contracts start happening. You're right, some of these large contracts have delivery dates over time.
You get a lot of lead time in being able to say, Oh, what's the status? I think we're pretty thoughtful around what's always gone in our RPO balance. We've been considerate of that. There's always been that taken into account when we publish that bookings number and publish the RPO balance.
The more relevant question, of course, is how Microsoft can handle the concentration risk of having "whale" AI contracts drive the majority of growth. Their point of view is that they are building their whole infrastructure and software stack to be fungible (i.e., if OpenAI doesn't consume that $250B consumption contract because it never generates enough revenue to begin with), the infrastructure will still be used for other use cases across Microsoft's full portfolio. This is also why the hyperscaler business and AI inference specifically is essentially a "sport of kings." There are other very large businesses that help Microsoft, Amazon, and Google manage the massive capacity buildouts in a way that is simply not realistic for new entrants like CoreWeave, who will have to close shop and sell the hardware at pennies on the dollar if their future committed contracts don't end up consuming.
GCP

Source: Perplexity Finance
Back in August, I reviewed the thesis that GCP is undervalued:
For investors: Alphabet appears to be temporarily mispriced because the market can't see beyond the dying cash cow of search. Knowing how the cloud business of Amazon and Microsoft ended up overtaking their original businesses, it appears that GCP+Gemini will follow the same cycle. The risk here is whether they can become the number one AI player given that they own the full stack, but at these valuations, investors are getting the AI transformation at a steep discount.
Today, the situation looks quite different after a monster run and most analysts having revised their price targets well above $300. While the last six months have seen significant gains for Microsoft (20%) and AWS stock as well (30%), clearly the market rewarded the team for their execution.
Sundar Pichai, CEO, Alphabet and Google: Next, Google Cloud.
Our complete enterprise AI product portfolio is accelerating growth in revenue, operating margins, and backlog. In Q3, customer demand strengthened in three ways.
One, we are signing new customers faster. The number of new GCP customers increased by nearly 34% year-over-year.
Two, we are signing larger deals. We have signed more deals over $1 billion through Q3 this year than we did in the previous two years combined.
Third, we are deepening our relationships. Over 70% of existing Google Cloud customers use our AI products, including Banco BV, Best Buy, and FairPrice Group.
As we scale, we are diversifying revenue. Today, 13 product lines are each at an annual run rate over $1 billion, and we are improving operating margin with highly-differentiated products built with our own technology.
This deep product differentiation starts with our AI infrastructure. We have a decade of experience building AI Accelerators and today offer the widest array of chips. This leadership is winning customers like HCA Healthcare, LG AI Research, and Macquarie Bank, and it's why nine of the top ten AI labs choose Google Cloud.
We are also the only Cloud provider offering our own leading generative AI models, including Gemini, Imagen, Veo, Chirp and Lyria. Adoption is rapidly accelerating. In Q3, revenue from products built on our generative AI models grew more than 200% year-over-year.
Over the past 12 months, nearly 150 Google Cloud customers each processed approximately one trillion tokens with our models for a wide range of applications. For example, WPP is creating campaigns with up to 70% efficiency gains. Swarovski has increased email open rates by 17% and accelerated campaign localization by 10x.
Earlier this month, we launched Gemini Enterprise, the new front door for AI in the workplace, and we are seeing strong adoption for agents built on this platform. Our packaged enterprise agents in Gemini Enterprise are optimized for a variety of domains, are highly differentiated and offer significant out-of-box value to customers. We have already crossed two million subscribers across 700 companies.
GCP has been a bit of a mixed bag, with a lot of reps going through performance improvement plans and team restructuring. There was a need for a new sales culture to be formed, a process that has also been happening in parallel in AWS. In theory, they have the deepest AI stack advantage, and later this year they will likely have the best-performing model once Gemini 3.0 Pro and Flash launch. Still, most of the year has been overshadowed by the meteoric rise of Claude Code (and OpenAI's Codex), with xAI also going aggressively after the market share previously occupied by Gemini.

Source: OpenRouter monthly ranking
Anat Ashkenazi, SVP and CFO, Alphabet and Google: Turning to the Google Cloud segment, which again delivered very strong results this quarter as Cloud continued to benefit from our enterprise AI optimized stack, including our own custom TPUs and our industry-leading AI models.
Cloud revenue increased by 34% to $15.2 billion in the third quarter, driven by strong performance in GCP, which continued to grow at a rate that was much higher than Cloud's overall revenue growth rate.
GCP's growth was driven by enterprise AI products, which are generating billions in quarterly revenue.We had strong growth in enterprise AI Infrastructure and enterprise AI solutions, which benefited from demand for our industry-leading models, including Gemini 2.5.
Core GCP was also a meaningful contributor to growth.
And we had double-digit growth in Workspace, which was driven by an increase in average revenue per seat and the number of seats.
Cloud operating income increased by 85% to $3.6 billion, and operating margin increased from 17.1% in the third quarter last year to 23.7% this quarter.
The expansion in Cloud operating margin was driven by strong revenue performance and continued efficiencies in our expense base, partially offset by higher technical infrastructure usage costs, which includes depreciation expense and other operations costs, such as energy.
Google Cloud's backlog increased 46% sequentially and 82% year-over-year, reaching $155 billion at the end of the third quarter. The increase was driven primarily by strong demand for enterprise AI.
As Sundar mentioned earlier, Cloud has signed more billion-dollar deals in the first nine months of 2025 than in the past two years combined.
Still, something has clearly clicked, even if GCP is benefiting from strong portfolio performance across the full Alphabet group of companies (and analysts no longer being spooked by the impact of AI Mode in Google Search). Their backlog of $155B is also quite impressive, relevant to the context that they operate in.
Eric Sheridan (Goldman Sachs): Thank you so much for taking the questions.
Sundar, when you think about your custom silicon efforts across the organization, can you reflect a little bit about the opportunity set you see with each passing generation of custom silicon, both in terms of driving operating efficiencies inside the organization and potentially increased monetization efforts around those outside of the organization?
Sundar Pichai, CEO, Alphabet and Google: Eric, overall, I would say we are seeing substantial demand for our AI infrastructure products, including TPU-based and GPU-based solutions. It is one of the key drivers of our growth over the past year, and I think on a going-forward basis, I think we continue to see very strong demand, and we are investing to meet that.
I do think a big part of what differentiates Google Cloud, effectively, we have taken a deep full-stack approach to AI, so we are -- and that really plays out. We are the only hyperscaler who is really building offerings on our own models.
And we are also highly differentiated on our own technology. So to your question, I think that does give us the opportunity to continue driving growth in operating margins in Cloud, as we have done in the past.
And also, I think from a revenue sets, the infrastructure portion of our business to be a growth driver looking ahead as well.
Similar to what we saw from AWS, there is a big focus on the potential business opportunity that TPUs represent, both for internal usage and with their preferred partners. Back on 10/23, they announced a deal with Anthropic for 1GW of capacity being deployed, which some took as essentially meaning the run rate for GCP has doubled. This was my comment on X:
So when we say that 1GW build out equals "$50B consumption for GCP", that's probably not how it will work, but it's still an important win for them. The $50B is the capex required to build it out and run it over the useful lifecycle of deployment. Now in theory that means Anthropic renting everything out for 5 years should end up at at least $50B of revenue, but the details matter a lot:
1. The $50B capex is based on paying NVIDIA its margins, which Google bypasses here. What the actual cost would look like over the build out depends on their terms with Broadcom or MediaTek (who might service some of the workload), but a recent 1GW capacity they announced to be built in India cost is equivalent to around $15B of capex. Where these workloads will sit is relevant to the total running cost.
2. GCP discounts for multi-year commits get aggressive, and this is obviously an exceptional deal. Practically speaking, I doubt they would do the deal for less than $12B–$15B ARR.
3. Over five years that's going to beat the $50B figure, but that assumes that Anthropic uses the full capacity at all times AND that they don't need to discount Y4–Y5 a lot more aggressively as newer generations of chips get onboarded with higher efficiency.
In any case, this is an amazing win for the team, but realistically speaking, I don't know if it will add more than $15B to the annual run rate, and that amount would only come into play once the full build out is done and Anthropic actually consumes that capacity.
The obvious question is also: "Is 1GW of compute used by Anthropic as valuable for GCP's run rate as 1GW of compute on Gemini?", particularly since the goal should be to deliver the best coding model and agentic workloads on the market over the next 24 months. I would be surprised if there isn't a natural moment where both parties might prefer a change in the deal terms.
Still, investors are really focused on the AI Overviews in Google Search:
Ken Gawrelski (Wells Fargo): Thank you very much. Two questions, please.
First, it appears more and more clear that all the new modes at Google, with Gemini, AI Overviews, AI Mode, even ChatGPT, is growing the addressable market for engagement in search-like behavior. Could you talk about what gives you confidence that it will also grow the addressable market for marketing activity and overall revenue associated with that behavior? That's question one.
Question two is just more about, as you think about AI Mode, AI Overviews, and traditional Google Search, how do you think, do you see a world in 12 to 24 months, those all co-exist, and does the user eventually pick what mode they want? Does the algorithm pick the mode? Can you talk a little bit about how you think that will progress over the next 12 to 24 months? Thank you very much.
Sundar Pichai, CEO, Alphabet and Google: Ken, thanks.
Look, I think it's a dynamic moment, and I think we are meeting people in the moment with what they are trying to do.
Obviously, Search is evolving, and between AI Overviews and AI Mode, I think we are able to kind of give that range of experience for people in this moment.
Over time, you can expect us to make the experiences simpler in a way that -- just like we did universal search many, many years ago, we may have done text search, image search, video search, et cetera, and then we brought it together as universal search.So you will see evolutions like that, but I think we want to be sensitive to making sure that we are meeting the users in terms of what they are looking for.
I think Gemini allows us to build a more personal, proactive, powerful AI assistant for that moment, and I think having the two surfaces, Search and Gemini, allows us to really serve users across the breadth of their needs.But over time, we will thoughtfully look for opportunities to make the experience better for users.
And to the first part, I would broadly say, I do think we have been consistently saying for a while now this is an expansionary moment, and we are seeing people engage more, and I think when they do that, naturally, a portion of that information for users, those journeys are commercial in nature. So I would expect that to play out over time as well.
I think the core structural advantage for Google remains access to multiple user surfaces on both the consumer and enterprise sides that allow them to serve Gemini queries and derive downstream revenue. The other players have been lucky so far to benefit from a traditionally disjointed go-to-market approach from the leadership team, but this has clearly changed (or at least the perception is different).
Justin Post (BAML): Great. Just a couple.
Sundar, I think you mentioned Gemini 3 is coming. Maybe you could comment on the pace of innovation in frontier models. Is there still just a tremendous amount of innovation, or is it slowing at all?
And then, you mentioned a number of large deals signed in the last nine months for Cloud, which is great. Any changes in the economics of these deals, as far as long-term profitability? Anything we should be aware of? Thank you.
Sundar Pichai, CEO, Alphabet and Google: Thanks, Justin.
The first, on the pace of frontier model research and development. Look, I think two things are both simultaneously true. I'm incredibly impressed by the pace at which the teams are executing and the pace at which we are improving these models.
But it also is true at the same time that each of the prior models you're trying to get better over is now getting more and more capable.
So I think both the pace is increasing, but sometimes we are taking the time to put out a notably improved model. So I think that may take slightly longer.
But I do think the underlying pace is phenomenal to see, and I'm excited about our Gemini 3.0 release later this year.
On Cloud, I would point out as a sign of the momentum, I think the number of deals greater than $1 billion that we signed in the first three quarters of this year are greater than the two years prior. So we are definitely seeing strong momentum and we are executing at pace.
And in terms of long-term economics, I would say that, again, us being a full-stack AI player, and the fact that we are developing highly differentiated products on our own technology I think will help us drive a good trajectory here, as you have seen over the past few years.
There has been an ongoing hype campaign in the last month on X from many "well-connected" users who've been sharing performance examples from Gemini 3 Pro. If they hit it out of the park (at least similar performance to GPT-5 Codex High and Sonnet 4.5 Thinking), with lower cost to run and good integrations from the beginning within popular agentic coding tools, it's likely going to put a lot of pressure across the full ecosystem as token consumption swings towards GCP. Some might never recover.