
Why behind AI: Data centers in space
In the last weeks we had two announcements from major players (Google and NVIDIA) who are going ahead with well-funded projects to launch initial capacity and start testing the viability of such an approach. This is an interesting moment in the industry for two reasons:
It’s actually a very difficult problem to solve and probably a waste of resources short term.
It’s an indication that AI is considered such a valuable long-term play, that we are actually willing to push the limitations of physics in ways that we’ve only previously been able to do with semiconductors and EUV lithography.
Project Suncatcher is a moonshot exploring a new frontier: equipping solar-powered satellite constellations with TPUs and free-space optical links to one day scale machine learning compute in space.
Artificial intelligence (AI) is a foundational technology that could reshape our world, driving new scientific discoveries and helping us tackle humanity's greatest challenges. Now, we're asking where we can go to unlock its fullest potential.
The Sun is the ultimate energy source in our solar system, emitting more power than 100 trillion times humanity’s total electricity production. In the right orbit, a solar panel can be up to 8 times more productive than on earth, and produce power nearly continuously, reducing the need for batteries. In the future, space may be the best place to scale AI compute. Working backwards from there, our new research moonshot, Project Suncatcher, envisions compact constellations of solar-powered satellites, carrying Google TPUs and connected by free-space optical links. This approach would have tremendous potential for scale, and also minimizes impact on terrestrial resources.
We’re excited about this growing area of exploration, and our early research, shared today in “Towards a future space-based, highly scalable AI infrastructure system design,” a preprint paper, which describes our progress toward tackling the foundational challenges of this ambitious endeavor — including high-bandwidth communication between satellites, orbital dynamics, and radiation effects on computing. By focusing on a modular design of smaller, interconnected satellites, we are laying the groundwork for a highly scalable, future space-based AI infrastructure.
Project Suncatcher is part of Google’s long tradition of taking on moonshots that tackle tough scientific and engineering problems. Like all moonshots, there will be unknowns, but it’s in this spirit that we embarked on building a large-scale quantum computer a decade ago — before it was considered a realistic engineering goal — and envisioned an autonomous vehicle over 15 years ago, which eventually became Waymo and now serves millions of passenger trips around the globe.
The first thing that should be obvious here is that Google is not just supporting interesting research; they are actively trying to put their own hardware in space. This is a model that has a lot better long-term outlook than alternatives, since it allows for faster feedback loops and a feeling of ownership across multiple parts of the chain that will need to adapt to the (very likely and significant) failures.
System design and key challenges
The proposed system consists of a constellation of networked satellites, likely operating in a dawn–dusk sun-synchronous low earth orbit, where they would be exposed to near-constant sunlight. This orbital choice maximizes solar energy collection and reduces the need for heavy onboard batteries. For this system to be viable, several technical hurdles must be overcome:
1. Achieving data center-scale inter-satellite links
Large-scale ML workloads require distributing tasks across numerous accelerators with high-bandwidth, low-latency connections. Delivering performance comparable to terrestrial data centers requires links between satellites that support tens of terabits per second. Our analysis indicates that this should be possible with multi-channel dense wavelength-division multiplexing (DWDM) transceivers and spatial multiplexing.
However, achieving this kind of bandwidth requires received power levels thousands of times higher than typical in conventional, long-range deployments. Since received power scales inversely with the square of the distance, we can overcome this challenge by flying the satellites in a very close formation (kilometers or less), thus closing the link budget (i.e., the accounting of the end-to-end signal power losses in the communications system). Our team has already begun validating this approach with a bench-scale demonstrator that successfully achieved 800 Gbps each-way transmission (1.6 Tbps total) using a single transceiver pair.
2. Controlling large, tightly-clustered satellite formations
High-bandwidth inter-satellite links require our satellites to fly in a much more compact formation than any current system. We developed numerical and analytic physics models to analyze the orbital dynamics of such a constellation. We used an approximation starting from the Hill-Clohessy-Wiltshire equations (which describe the orbital motion of a satellite relative to a circular reference orbit in a Keplerian approximation) and a JAX-based differentiable model for the numerical refinement that accounts for further perturbations.
At the altitude of our planned constellation, the non-sphericity of Earth's gravitational field, and potentially atmospheric drag, are the dominant non-Keplerian effects impacting satellite orbital dynamics. In the figure below, we show trajectories (over one full orbit) for an illustrative 81-satellite constellation configuration in the orbital plane, at a mean cluster altitude of 650 km. The cluster radius is R=1 km, with the distance between next-nearest-neighbor satellites oscillating between ~100–200m, under the influence of Earth’s gravity.
The models show that, with satellites positioned just hundreds of meters apart, we will likely only require modest station-keeping maneuvers to maintain stable constellations within our desired sun-synchronous orbit.
Before we dive into their proposed approaches, let’s cover why a datacenter in space is a bit of a questionable idea.
Very high costs of deployment. While SpaceX has significantly changed the math of doing space launches, realistically speaking in the short term, we are unlikely to be able to put any sort of capacity that would be able to return its investment from electricity costs alone.
Radiation damage. On a recent test over 18 months in orbit, 9 out of 20 solid-state drives failed due to radiation exposure. Which leads us to the next obvious challenge:
Maintenance. Modern datacenters operate like a clockwork thanks to a very competent and proactive army of technicians. Getting them to proactively fix quickly the likely failure rate of 50%+ while being very costly to bring to those satellites (or their robotic alternatives, together with the actual replacement inventory) is an operational nightmare.
Cooling. This is a bit counterintuitive, but vacuum makes dissipating heat really difficult. While I think this will be something we are able to optimize for long term, in the short term it remains a significant add-on cost in terms of resources needed for heat management.
Now coming back to Google’s project. Their goal is to put TPUs integrated on the satellites themselves, then fly them very closely in order to wirelessly sync the clusters. The benefit of this approach is that you can still get access to a much higher amount of solar energy, while shipping fully configured satellites in low orbit and being able to operate them immediately.
3. Radiation tolerance of TPUs
For ML accelerators to be effective in space, they must withstand the environment of low-Earth orbit. We tested Trillium, Google’s v6e Cloud TPU, in a 67MeV proton beam to test for impact from total ionizing dose (TID) and single event effects (SEEs).
The results were promising. While the High Bandwidth Memory (HBM) subsystems were the most sensitive component, they only began showing irregularities after a cumulative dose of 2 krad(Si) — nearly three times the expected (shielded) five year mission dose of 750 rad(Si). No hard failures were attributable to TID up to the maximum tested dose of 15 krad(Si) on a single chip, indicating that Trillium TPUs are surprisingly radiation-hard for space applications.
4. Economic feasibility and launch costs
Historically, high launch costs have been a primary barrier to large-scale space-based systems. However, our analysis of historical and projected launch pricing data suggests that with a sustained learning rate, prices may fall to less than $200/kg by the mid-2030s. At that price point, the cost of launching and operating a space-based data center could become roughly comparable to the reported energy costs of an equivalent terrestrial data center on a per-kilowatt/year basis[1]. See the preprint paper for more details.
The pitch is further improved because initial tests indicated that the TPU components might be more resistant to radiation than previous technology brought to space, and due to the very specific approach of shipping fully assembled satellites in low orbit, costs are likely to become increasingly manageable within a few years.
Our initial analysis shows that the core concepts of space-based ML compute are not precluded by fundamental physics or insurmountable economic barriers. However, significant engineering challenges remain, such as thermal management, high-bandwidth ground communications, and on-orbit system reliability.
To begin addressing these challenges, our next milestone is a learning mission in partnership with Planet, slated to launch two prototype satellites by early 2027. This experiment will test how our models and TPU hardware operate in space and validate the use of optical inter-satellite links for distributed ML tasks.
Eventually, gigawatt-scale constellations may benefit from a more radical satellite design; this may combine new compute architectures more naturally suited to the space environment with a mechanical design in which solar power collection, compute, and thermal management are tightly integrated. Just as the development of complex system-on-chip technology was motivated by and enabled by modern smartphones, scale and integration will advance what’s possible in space.
If successful, the next step for them would be to start investing more in designing space-specific data center architecture. This is a reasonable staged rollout, if rather slow, no pun intended, to take off. Currently, this is also limited to machine learning workloads for training, but to be fair, the value of the actual compute output is a lot less relevant than demonstrating being able to operate this at a scale.
“In space, you get almost unlimited, low-cost renewable energy,” said Philip Johnston, cofounder and CEO of the startup, which is based in Redmond, Washington. “The only cost on the environment will be on the launch, then there will be 10x carbon-dioxide savings over the life of the data center compared with powering the data center terrestrially on Earth.”
Starcloud’s upcoming satellite launch, planned for November, will mark the NVIDIA H100 GPU’s cosmic debut — and the first time a state-of-the-art, data center-class GPU is in outer space.
The 60-kilogram Starcloud-1 satellite, about the size of a small fridge, is expected to offer 100x more powerful GPU compute than any previous space-based operation.
Project Starcloud is a lot louder than how Google positioned their venture. They are an independent startup that has raised over $20M in funding and are trying to build actual data centers in space.
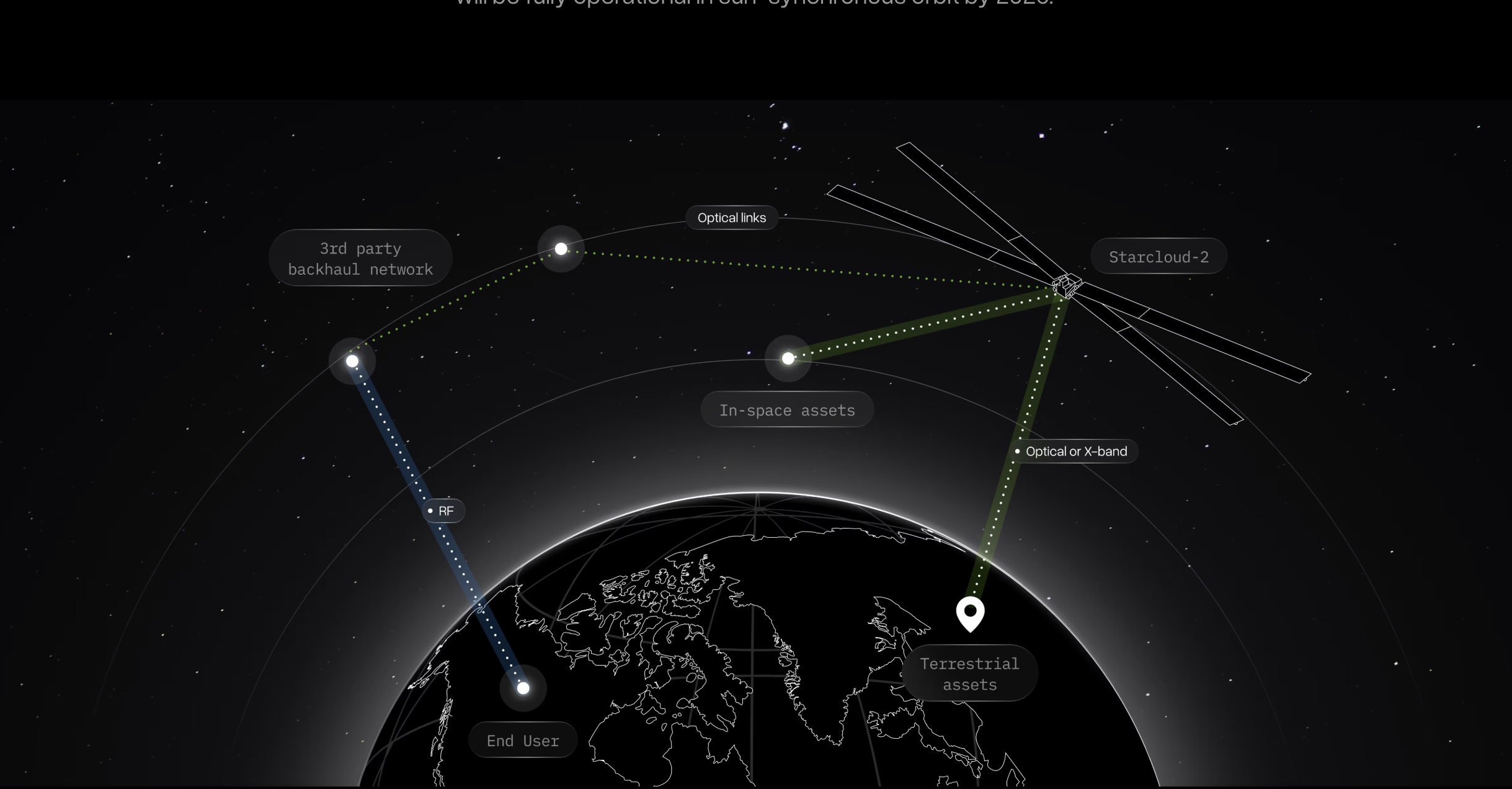
Source: Starcloud 2
Rather than running ML workloads, the goal is to actually support inference and data processing for other assets in space.
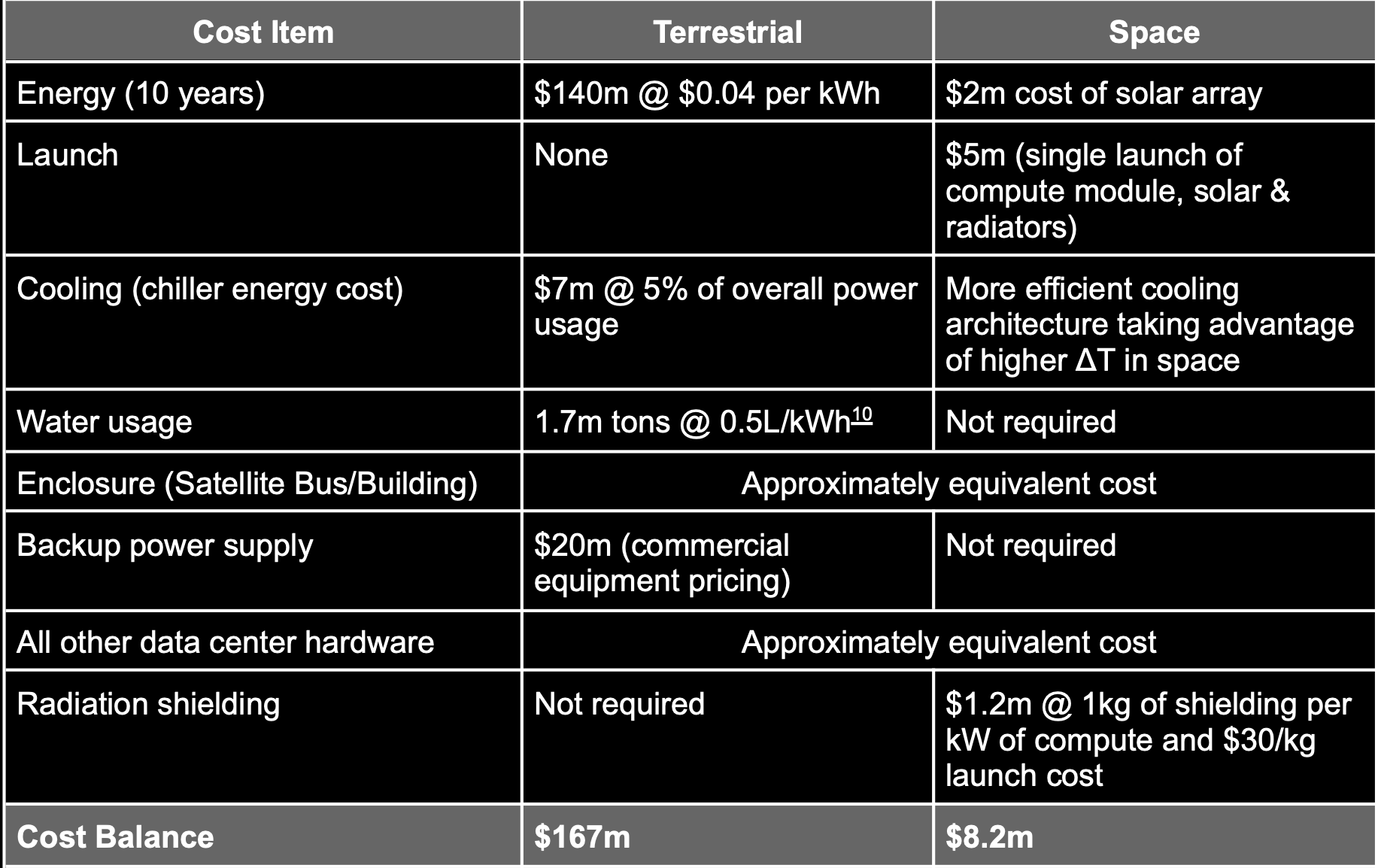
Source: Starcloud white paper
Rather than running ML workloads, the goal is to actually support inference and data processing for other assets in space.
The basic design principles below were adhered to when creating the concept design for GW scale orbital data centers. These are all in service of creating a low-cost, high-value, future-proofed data center.
1. Modularity: Multiple modules should be able to be docked/undocked independently. The requirements for each design element may evolve independently as needed. Containers may have different compute abilities over time.
2. Maintainability: Old parts and containers should be easy to replace without impacting large parts of the data center. The data center should not need retiring for at least 10 years.
3. Minimize moving parts and critical failure points: Reducing as much as reasonably possible connectors, mechanical actuators, latches, and other moving parts. Ideally each container should have one single universal port combining power/network/cooling.
4. Design resiliency: Single points of failure should be minimized, and any failures should result in graceful degradation of performance.
5. Incremental scalability: Able to scale the number of containers from one to N, maintaining profitability from the very first container and not requiring large CapEx jumps at any one point.
The overall design makes sense, assuming being able to bring and replace modules is economically feasible on a scaled deployment. They will also already launch an initial version this November and have an extensive selection of financial backers and technical partners. It’s clear that the project is designed to fit within the ecosystem, but if functional, can scale into a full-fledged platform. The big omission here is space debris; i.e., they might solve the thermal and radiation challenges and still get blasted by a space rock.

Source: delian on X
Delian Asparouhov has been one of the loudest "data centers in space" bears on the timeline and someone with the pedigree to have an opinion as the cofounder of Varda, a space research company that essentially manufactures pharmaceutical components in microgravity. One of his engineers had a bit longer take that’s relevant here:
Data centers in orbit? Of course that’s your contention. Of course it is.
You just finished watching a Scott Manley video on radiative heat transfer and now you think you’re gonna disrupt AWS with a few solar panels and a rideshare slot. You’re gonna believe that right up until next month when you crack open DeWitt and Incropera and start throwing around σT⁴ like you just invented radiation physics, quoting emissivity tables for polished aluminum like they’re forbidden knowledge.
Then you’ll finally open SMAD and realize your radiator isn’t some static plate glowing into the void. It’s a dynamic structure with a wicked case of thermal flutter reminiscent of Hubble’s arrays. You’ll be quoting beta angles and Earth albedo coefficients and wondering why your deployable array grenaded in vibe when the first bending mode clocked in at 38 Hz instead of the 50 Hz you promised in CDR.
After that you’ll get real ambitious, quoting Johnson and Fabisinski on inflatable polyimide PV structures, pretending you actually understand what happens when your 25-micron Kapton sail is tensioned off a Toray T1100G Cycom 5250-4 boom that has been sun-baked at 120 °C for six months in LEO. You’ll cite “areal density optimization” like gospel while your resin creeps, your modulus drops, and your perfectly flat film turns into a potato chip. "Well, as a matter of fact, I won’t, because launch costs are about to fall another order of magnitude once Starship hits cadence. The cost per kilo will—" Drop by tenfold and the economics flip.
Yeah, I’ve heard that one. The Wired 2012 quote, “You wouldn’t build a Boeing 747 and throw it away after one flight.” I remember. I even asked him about that over lunch once, whether the market was actually elastic enough to handle the supply increase from reusability. Turns out it wasn’t. Non-Starlink launch mass in the United States grew at 13.7 percent CAGR from 2015 to 2023. Payload demand didn’t scale with flight cadence, so prices didn’t collapse, margins just swelled. That’s why they had to invent Starlink.
When the market can’t absorb your rockets, you start building your own payloads. Is that your thing? You read some Marc Andreessen “American Dynamism” manifesto and suddenly start ignoring the engineering realities? You start throwing around a few buzzwords to impress the Twitter anons and earn some street cred for having a contrarian opinion? One, don’t do that. Two, you dropped a 500-thousand-dollar seed check on a concept that could have been debunked by a dollar-fifty worth of tokens from Grok. "Well, at least I’m a capital allocator. We’ll be skiing in Hokkaido while you’re doing bolt preload calculations for some bridge somewhere." Yeah, maybe.
But at least I won’t be unoriginal or anonymous. I’m out here asking why the hell we’d melt the brains of a thousand aerospace engineers just to save four cents per kilowatt-hour on solar electricity. First principles isn’t about getting nerd-sniped by a shiny-object problem. It’s about asking whether we should be solving that problem at all. But hey, if you’ve got an issue with that, we can always take it up with E.
I think that the problem is worth solving because it’s part of what our long-term expansion for resources outside of the Earth looks like. As computing power becomes more critical, it’s not difficult to see how we will likely not be waiting on Grok to ping back API responses over to Mars from Colossus, but will be hosted in local (or space) data centers. The same way that the Moon landing was technically pointless, it triggered the majority of technical innovation that we’ve seen in the last 50 years. Data centers in space might be a "top signal" or could be an indication that many in tech are starting to seriously consider whether their dreams can become reality.