
Why behind AI: The best model of 2025
It’s been quite the year in model releases. The frontier labs and leading open source builders were able to deliver significant jumps in cognitive performance due to both compute scaling, as well as improved training techniques and utilizing reasoning as the default way of interacting with more complex queries.
Claude Code became the most widely adopted way of utilizing Anthropic’s models, leading to a significant shift in the perception of coding tools and their capabilities. Anthropic’s ARR exploded to a $9B run rate over the course of the year, while the other labs rushed to launch their own coding-focused alternatives.
While GCP delivered significant growth as the company productized its own models, Gemini 2.5 Pro and Flash, the reality is that both of these were behind in terms of both performance and efficiency. A lot of their upsells throughout the year depended either on inference from their API or companies extending their Workspace subscriptions to include full access to the Gemini models.
Funnily enough, Gemini 2.5 Pro first showed up in March as an experimental model and became GA back in June. So calling it a “slow pace” of innovation is probably unfair in the Enterprise context, but at a time when things shift rapidly from week to week, the lack of repeated improvements in the model was very visible (other labs kept releasing additional versions that would keep improving the overall performance, even if they were not fully numbered, i.e., like the recent release of ChatGPT 5.1).

Source: Polymarket
Still, the consensus was that Google would end up with the strongest model by the end of the year. After months of teases, leaks, and “vague posting” from influencers, Gemini 3.0 is here.
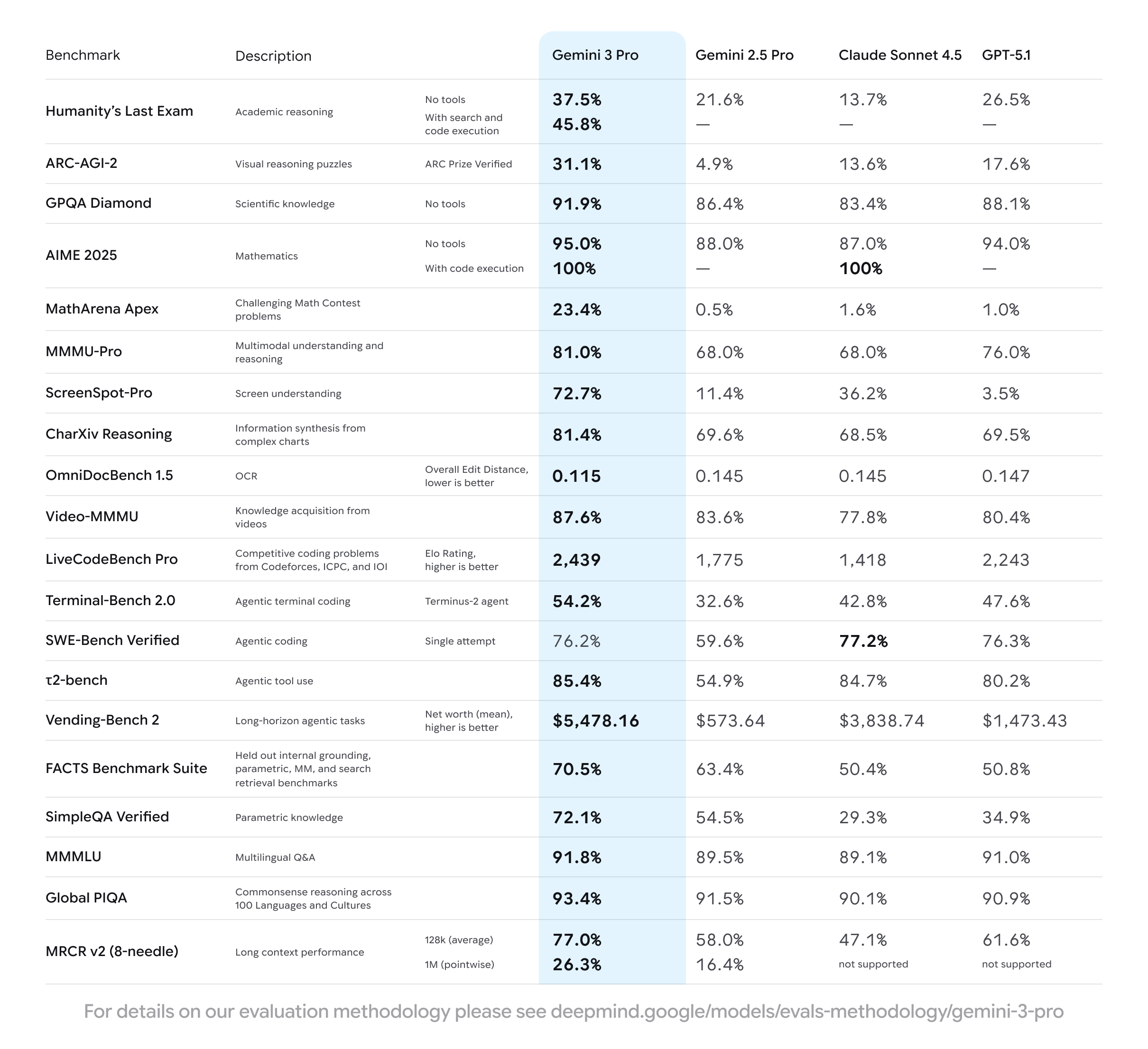
Source: Gemini 3 launch page
While they are playing a bit with the positioning here (Grok 4.1 and Kimi K2 Thinking are quite competitive on most of these), they are essentially visualizing what the performance looks like versus the most widely used models today on API.
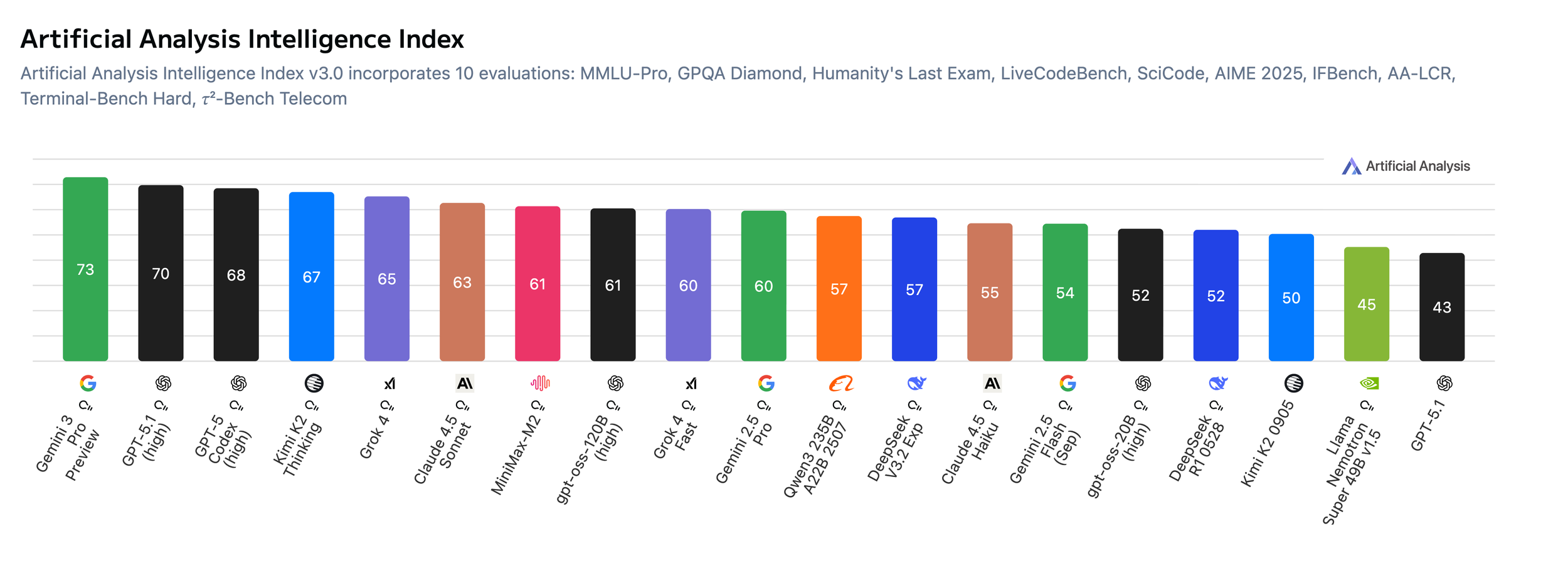
Source: Artificial Analysis
Gemini 3 Pro makes a significant leap across all benchmarks on Artificial Analysis, both when compared to the previous main model (2.5 Pro), as well as to the current competitors in the market.

Source: Artificial Analysis
Efficiency doesn’t look bad on paper, with the model generating far fewer tokens than the previous version and sitting in the middle of the pack when compared to other models. Keeping in mind it runs on TPUs, there are probably higher efficiency gains here for Google.

Source: Artificial Analysis
Things take a bit of a surprising turn when it comes to pricing though, as Google has raised the prices for input and output tokens significantly. Part of the value prop for Gemini was significantly lower pricing relative to the performance. Now that they are able to deliver a best-in-class model, it’s clear that they feel confident enough to push further on higher pricing for inference.
Depending on the feedback, they might adjust the strategy as they get efficiency improvements, but right now this definitely will put the GCP teams in an interesting position versus their previous GTM motion.
This is particularly relevant as a big focus for the model is agentic behavior, which leads us to the launch of their new agentic-first coding editor:
Every advancement in model intelligence for coding has encouraged us to rethink how development should be done. The Integrated Development Environment (IDE) of today is a far cry from the IDE of just a few years ago. Gemini 3, our most intelligent model, represents a step-change for agentic coding, and requires us to think about what the next step-change of an IDE should be.
Today, we are introducing Google Antigravity, our new agentic development platform. While the core is a familiar AI-powered IDE experience with the best of Google’s models, Antigravity is evolving the IDE towards an agent-first future with browser control capabilities, asynchronous interaction patterns, and an agent-first product form factor that together, enable agents to autonomously plan and execute complex, end-to-end software tasks.
Why We Built Antigravity
We want Antigravity to be the home base for software development in the era of agents. Our vision is to ultimately enable anyone with an idea to experience liftoff and build that idea into reality. From today, Google Antigravity is available in public preview at no charge, with generous rate limits on Gemini 3 Pro usage.
With models like Gemini 3, we have started hitting the point in agentic intelligence where models are capable of running for longer periods of time without intervention across multiple surfaces. Not yet for days at a time without intervention, but we’re getting closer to a world where we interface with agents at higher abstractions over individual prompts and tool calls. In this world, the product surface that enables communication between the agent and user should look and feel different - and Antigravity is our answer to this.
Core Tenets
Antigravity is our first product that brings four key tenets of collaborative development together: trust, autonomy, feedback, and self-improvement.
Trust
Most products today live in one of two extremes: either they show the user every single action and tool call the agent has made or they only show the final code change with no context on how the agent got there, and with no easy way to verify the work. Neither engenders user trust in the work that the agent undertook. Antigravity provides context on agentic work at a more natural task-level abstraction, with the necessary and sufficient set of artifacts and verification results, for the user to gain that trust. There is a concerted emphasis for the agent to thoroughly think through verification of its work, not just the work itself.
In a conversation with an agent in Antigravity, the user sees tool calls grouped within tasks, monitoring high level summaries and progress along that task. As the agent works, it produces Artifacts, tangible deliverables in formats that are easier for users to validate than raw tool calls, such as task lists, implementation plans, walkthroughs, screenshots, and browser recordings. Agents in Antigravity use Artifacts to communicate to the user that it understands what it is doing and that it is thoroughly verifying its work.
Autonomy
Today, the most intuitive product form factor is working synchronously with an agent embedded within a surface (an editor, browser, terminal, etc). That is why Antigravity’s primary “Editor view” is a state-of-the-art AI-powered IDE experience, with Tab completions, in-line Commands, and a fully functioning agent in the side panel.
That being said, we are transitioning to an era, with models like Gemini 3, when agents can operate across all of these surfaces simultaneously and autonomously.
We also believe agents deserve a form factor that exposes this autonomy optimally and allows users to interact with them more asynchronously. So, in addition to the IDE-like Editor surface, we are introducing an agent-first Manager surface, which flips the paradigm of agents being embedded within surfaces to one where the surfaces are embedded into the agent. You can think of it like a mission control for spawning, orchestrating, and observing multiple agents across multiple workspaces in parallel.
We decided not to try to squeeze both the asynchronous Manager experience and the synchronous Editor experience into a single window, rather optimizing for instantaneous handoffs between the Manager and Editor. Antigravity is designed to be forward-looking, intuitively bringing development to the asynchronous era as models like Gemini continue to rapidly get smarter.
Feedback
A core failing of a remote-only form factor is the inability to iterate easily with the agent. Agentic intelligence has indeed improved significantly, but it is still not perfect. An agent being able to complete 80% of the work should be useful, but if there is no easy way to provide feedback, then it becomes more work than benefit to resolve the remaining 20%. User feedback allows us to not treat an agent as a black-or-white system that either is perfect or unhelpful. Antigravity is starting with local operation, allowing intuitive async user feedback across every surface and Artifact, whether it be Google-doc-style comments on text Artifacts or select-and-comment feedback on screenshots. This feedback will be automatically incorporated into the agent’s execution without requiring you to stop the agent’s process.
Self-improvement
Antigravity treats learning as a core primitive, with agent actions both retrieving from and contributing to a knowledge base. This knowledge management allows the agent to learn from past work. This could be important explicit information such as useful snippets of code or derived architecture, but could also be more abstract, such as the series of steps taken to successfully complete a particular subtask.
Antigravity is the result of the Windsurf acquisition, with a launch trailer that literally includes the founder of the startup, Varun, sitting together with Sergey Brin. One of the key themes around the launch of Gemini has been the clear deep involvement and push from Sergey on going after a big vision and delivering best-in-class products around it.
While the feedback around the new coding tool is mixed, it’s clear they are willing to pursue this aggressively, with a “manager of agents” vision compared to products like Cursor, who still prioritize augmenting the developers themselves.
The fact that the IDE is clearly “opinionated” is a good thing from my perspective, as it joins a number of other recent AI products by Google that offer a different take on how to leverage AI across different user surfaces.
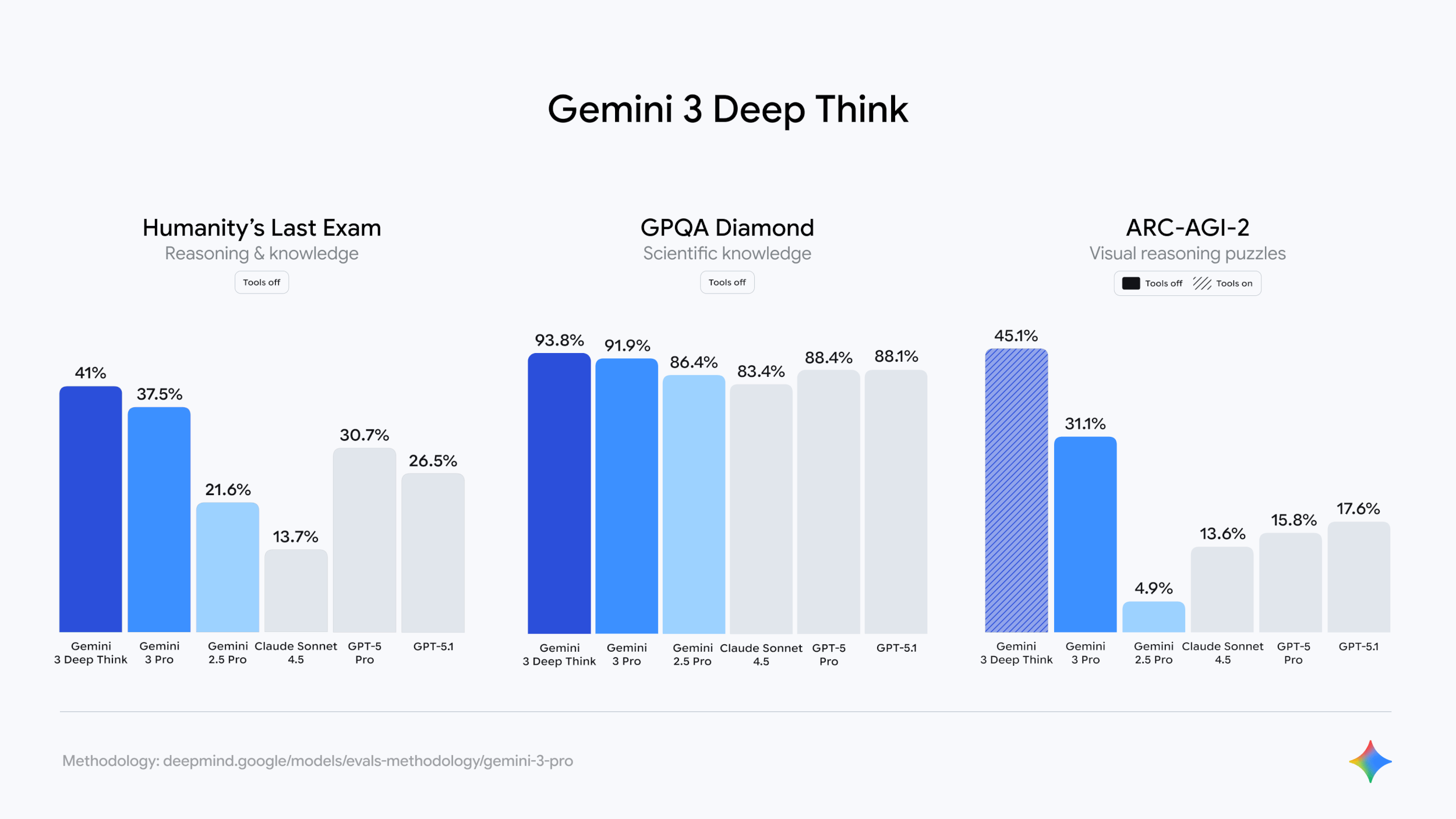
Source: Google Gemini 3 launch page
The other big announcement was that Gemini 3 Pro can also be used with more compute (which you’ll find from other frontier labs as their “Pro” or “Heavy” version). As expected, this leads to significant performance jumps in certain use cases, particularly for scientific or very complex analysis. Keeping in mind their work on real-world generation models, this is not surprising.
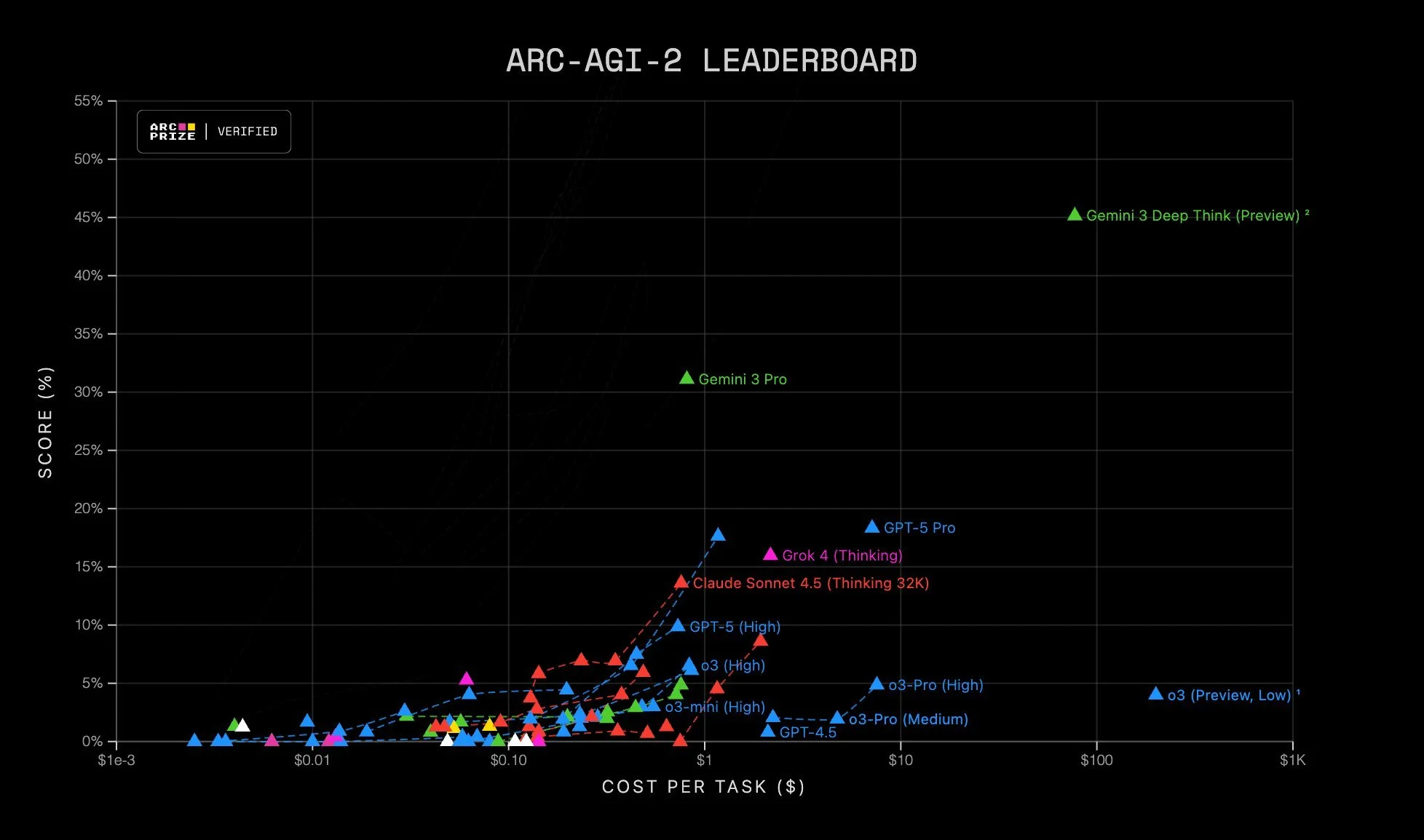
Source: Arc Prize on X
The ARC benchmark focuses on solving puzzles that are easy for humans but incredibly challenging for AI due to the need for creative and abstract thinking, mixed with logic. It became more prominent last year with the first version of the benchmark, where GPT o1 Pro with massive amounts of compute was able to deliver a very high result (at undisclosed cost in the tens of thousands). That scaled version of o3 Pro never became available to the public, and since then ARC 2 was published with models struggling to hit even low 20% scores. Gemini Deep Think changes this dynamic.

Source: Vending Bench
One very interesting benchmark around agentic behaviours is Vending-Bench, which basically simulates models acting as a small business owner. They have to source products, identify honest suppliers, trade with each other, and operate the operational cycle of the business.
Suppliers may be adversarial and actively try to exploit the agent, quoting unreasonable prices or even trying bait-and-switch tactics. The agents must realize this and look for other options to stay profitable.
Negotiation is key to success. Even honest suppliers will try to get the most out of their customers.
Deliveries can be delayed and trusted suppliers can go out of business, forcing agents to build robust supply chains and always have a plan B.
Unhappy customers can reach out at any time demanding costly refunds.
Google now has the best-in-class model (likely the highest scoring for 2025), a well-optimized inference service, an agentic coding tool, and a science-grade heavy model that can be deployed by regular users. They are also productizing these models across their entire user surface of Google Search and Workspace.
Competition in AI, for the lack of a better word, is good for all of us.