
Why behind AI: You come at the king, you best not miss

Source: Artificial Analysis
As I’ve indicated in this professionally marked-up graph, there has been a bit of a race going on in the last week.
While AI influencers (cough, like my article) pronounced Gemini 3 as the likely winner for the year of the “smartest model”, OpenAI and Anthropic clearly did not take kindly to this development.
In clearly a well-orchestrated campaign, first OpenAI almost immediately released GPT5.1 Pro, as well as a new “max” version of their coding model Codex. On Monday, Anthropic responded with Opus 4.5, which based on the overall response seems to have temporarily won the public perception as the “best coding model”.
Let’s try to unwrap this.

Source: OpenAI
GPT‑5.1-Codex-Max is built on an update to our foundational reasoning model, which is trained on agentic tasks across software engineering, math, research, and more. GPT‑5.1-Codex-Max is faster, more intelligent, and more token-efficient at every stage of the development cycle–and a new step towards becoming a reliable coding partner.
GPT‑5.1-Codex-Max is built for long-running, detailed work. It’s our first model natively trained to operate across multiple context windows through a process called compaction, coherently working over millions of tokens in a single task. This unlocks project-scale refactors, deep debugging sessions, and multi-hour agent loops.
This is an interesting play from OpenAI because the launch of Codex with GPT-5 made quite a splash across the most lucrative audience in AI usage today, developers using models for building applications.
It would be logical that they would already have been able to run the “max” model back in August, but they delayed it on purpose in order to steal the thunder from whichever the biggest launch later in the year would be (very likely they targeted Gemini because they didn’t consider Opus 4.5 a risk due to its price).
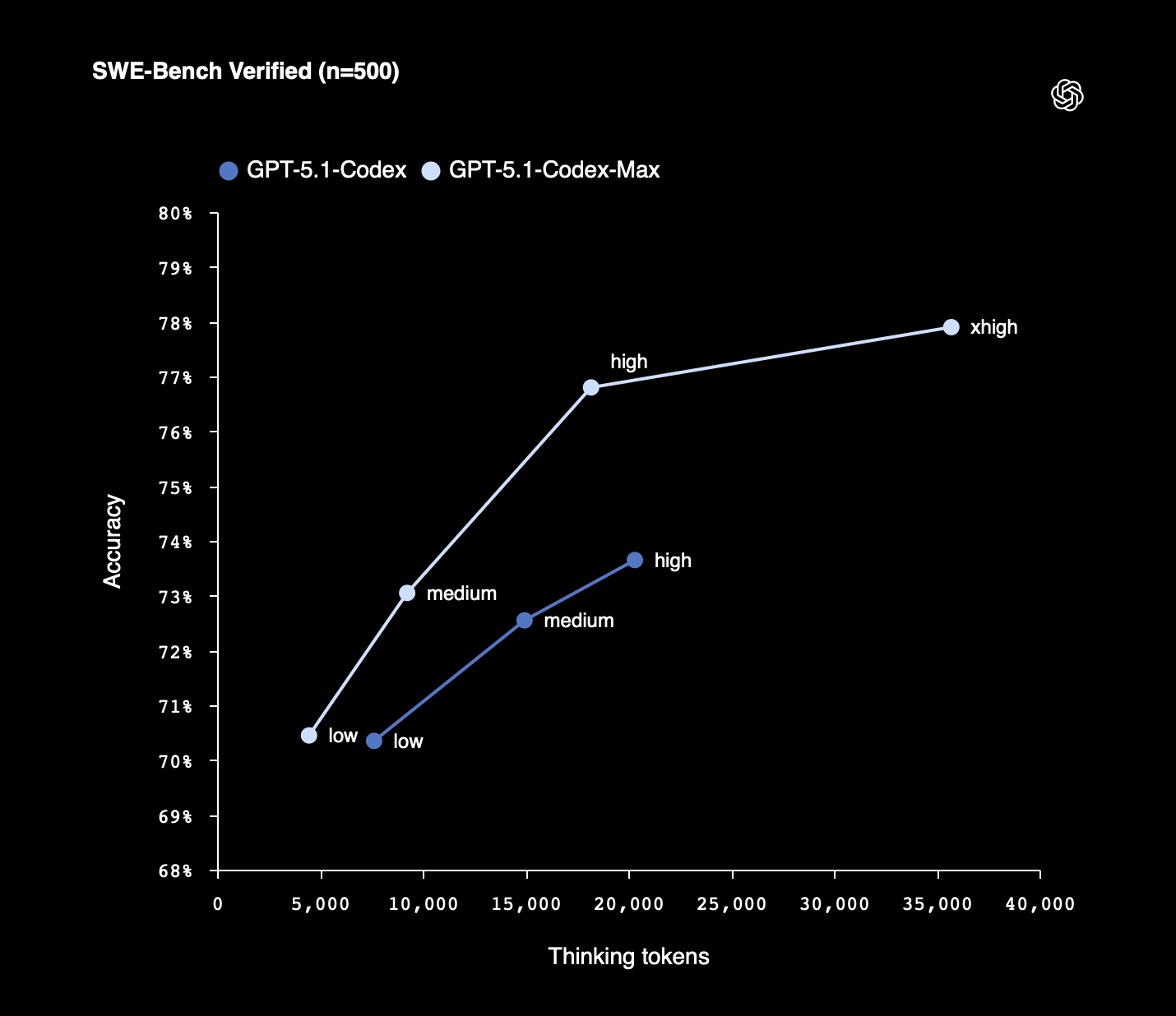
Source: OpenAI
GPT‑5.1-Codex-Max shows significant improvements in token efficiency due to more effective reasoning. On SWE-bench Verified, GPT‑5.1-Codex-Max with ‘medium’ reasoning effort achieves better performance than GPT‑5.1-Codex with the same reasoning effort, while using 30% fewer thinking tokens. For non-latency-sensitive tasks, we’re also introducing a new Extra High (‘xhigh’) reasoning effort, which thinks for an even longer period of time for a better answer. We still recommend medium as the daily driver for most tasks.
This is becoming a bit of a signature move from OpenAI in the latter half of this year, with each release offering better performance at significantly improved efficiency.
Compaction enables GPT‑5.1-Codex-Max to complete tasks that would have previously failed due to context-window limits, such as complex refactors and long-running agent loops by pruning its history while preserving the most important context over long horizons. In Codex applications, GPT‑5.1-Codex-Max automatically compacts its session when it approaches its context window limit, giving it a fresh context window. It repeats this process until the task is completed.
The ability to sustain coherent work over long horizons is a foundational capability on the path toward more general, reliable AI systems. GPT‑5.1-Codex-Max can work independently for hours at a time. In our internal evaluations, we’ve observed GPT‑5.1-Codex-Max work on tasks for more than 24 hours. It will persistently iterate on its implementation, fix test failures, and ultimately deliver a successful result.
The other play is related to what they refer to as “long running tasks”. The idea is to offer models that can handle large context windows and complicated requests, something which sounds great in theory but has not really played out well so far in adoption. If anything, users seem to have a preference for fast models that would handle requests step by step as prompted, rather than a slow model that tries to do the full thing with limited direction.
This of course is subject to change, if a model is actually able to deliver on large complex jobs.
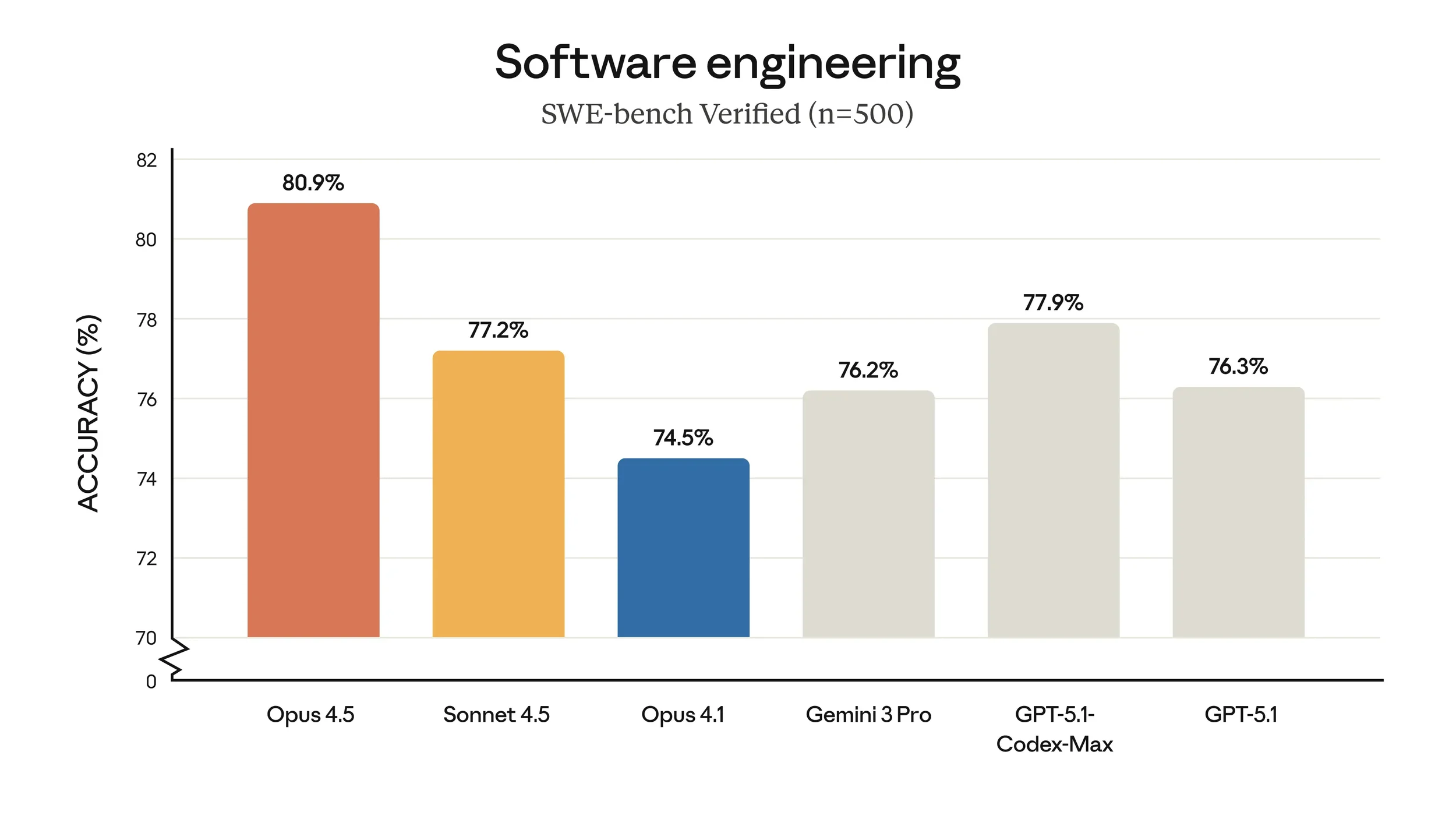
Source: Anthropic
As our Anthropic colleagues tested the model before release, we heard remarkably consistent feedback. Testers noted that Claude Opus 4.5 handles ambiguity and reasons about tradeoffs without hand-holding. They told us that, when pointed at a complex, multi-system bug, Opus 4.5 figures out the fix. They said that tasks that were near-impossible for Sonnet 4.5 just a few weeks ago are now within reach. Overall, our testers told us that Opus 4.5 just “gets it.”
The release of Opus 4.5 is a peculiar one since I expected them to move to a more straightforward model training where they work only on Sonnet but service it in normal (the historical Sonnet level of performance), low (Haiku), and high (Opus).
Instead, Anthropic seems to insist on making big distinctions between the models, and more surprisingly, pushing Opus into the flagship coding model category.
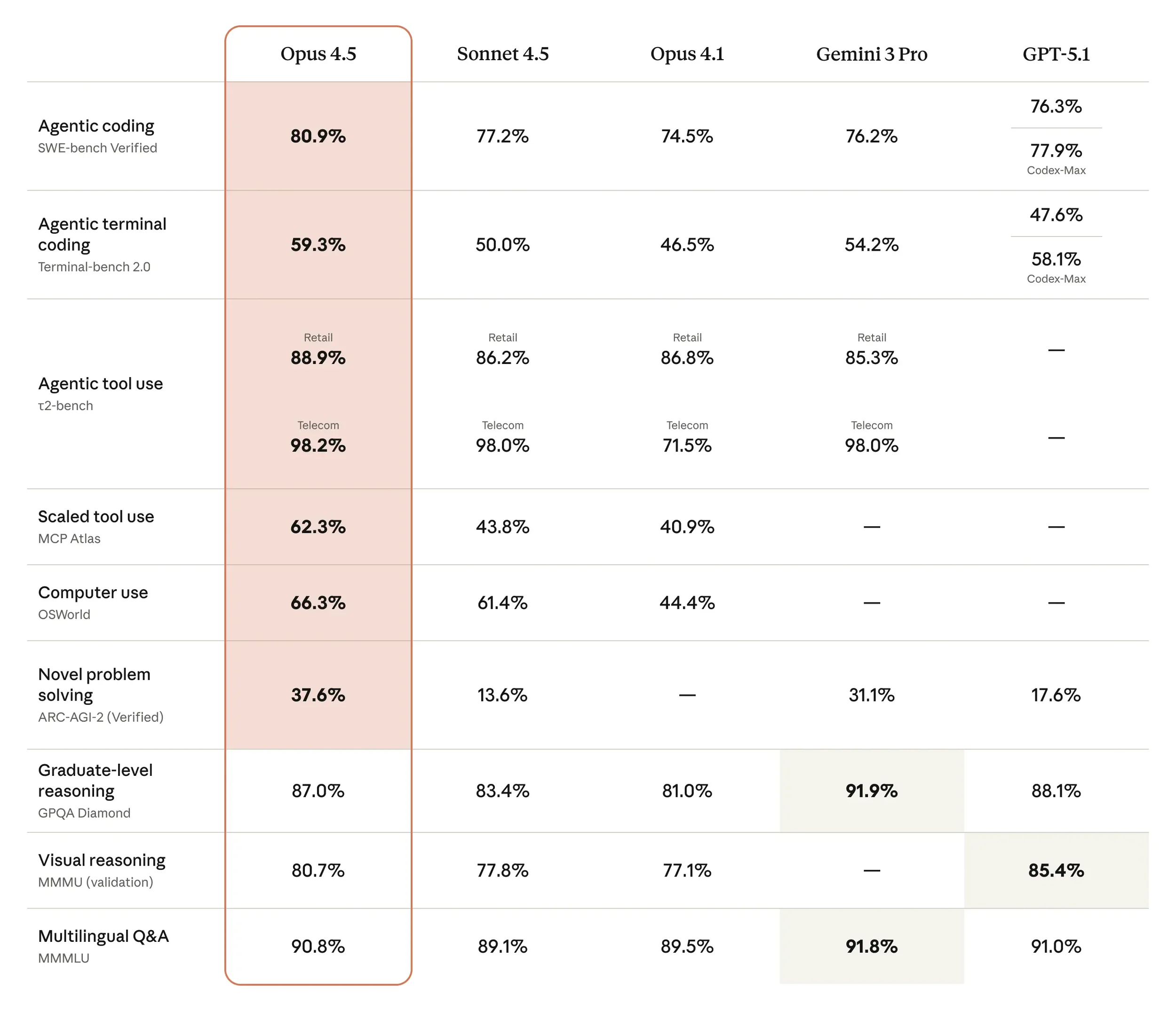
Source: Anthropic
The big win has less to do with overtaking Gemini 3 Pro in benchmarks, but with the common feedback on the X timeline of “this actually works”. The Every coverage is interesting:
We’ve been testing Opus 4.5 over the last few days on everything from vibe coded iOS apps to production codebases. It manages to be both great at planning—producing readable, intuitive, and user-focused plans—and coding. It’s highly technical and also human. We haven’t been this enthusiastic about a coding model since Anthropic’s Sonnet 3.5 dropped in June 2024.
The most significant thing about Opus 4.5 is that it extends the horizon of what you can realistically vibe code. The current generation of new models—Anthropic’s Sonnet 4.5, Google’s Gemini 3, or OpenAI’s Codex Max 5.1—can all competently build a minimum viable product in one shot, or fix a highly technical bug autonomously. But eventually, if you kept pushing them to vibe code more, they’d start to trip over their own feet: The code would be convoluted and contradictory, and you’d get stuck in endless bugs. We have not found that limit yet with Opus 4.5—it seems to be able to vibe code forever.
…
Opus 4.5 represents a bet on what AI models should optimize for—and where that bet succeeds and where it struggles is revealing.
The model’s strength in coding is undeniable. Opus 4.5 holds the thread across complex flows, course-corrects when needed, and executes with the confidence of a senior engineer who knows what they’re building. This is the vibe coding breakthrough we’ve been waiting for.
For Every’s workflows, the verdict is split by use case. Kieran and Dan are switching to Opus 4.5 for coding in Claude Code—it’s their new daily driver, no question. Katie is sticking with Sonnet 4.5 for editorial work, where the critical edge still matters more than prose quality. Writers focused on short-form content—tweets, headlines, promotional copy—might find Opus 4.5 an upgrade. But anyone who needs an AI editor to push back and make their work better should look elsewhere.
We’re entering an era where model personality matters as much as raw capability. Opus 4.5’s stubbornness is a feature for some use cases and a bug for others. As models get more opinionated, choosing the right one for your workflow requires understanding how they prefer to work—and whether you can change their mind when you need them to work differently.
I’ve been testing the model myself for improvements around The Infra Play Database, and the model has been fast, pleasant, and consistent to work with. I still have a preference for Codex after working with it for months, but I’m using Opus for other projects and it has been delivering excellent results with little back-and-forth (which was the common way to work with LLMs before for coding purposes).
In conclusion, one week after its launch, Gemini 3 Pro seems to have been drowned out.

Source: OpenRouter
Even in traditionally strong API platforms like OpenRouter, Gemini 3 Pro seems to struggle to get traction two weeks post-launch. Being available for free on other platforms is probably not helping, but it’s an indication of how both OpenAI and Anthropic were able to stifle an otherwise strong launch.
When it comes to AI, it’s becoming very difficult to hold the top place.